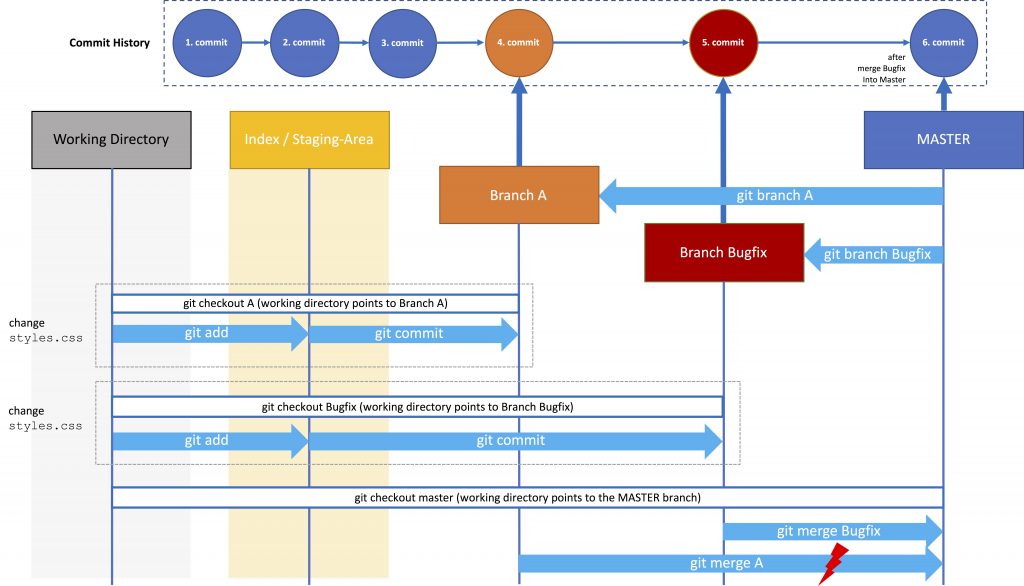
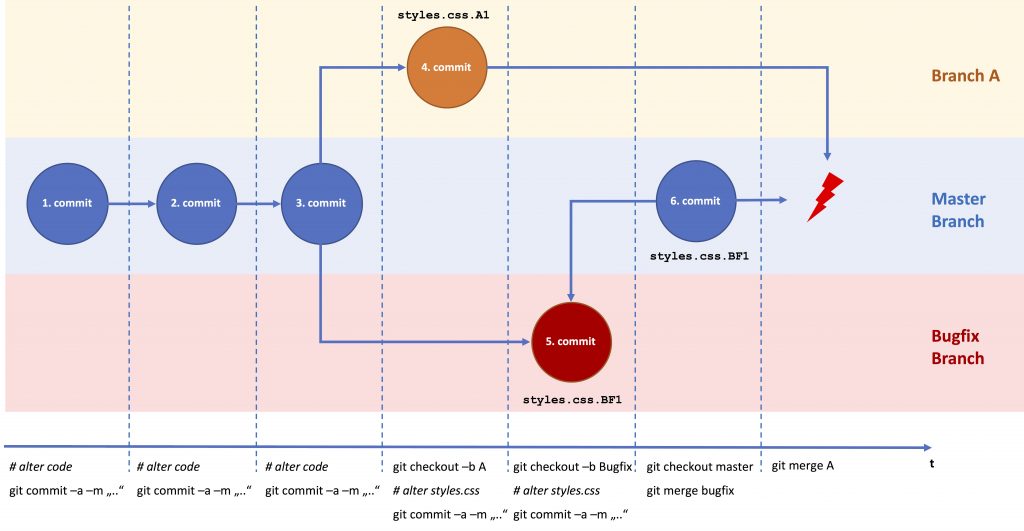
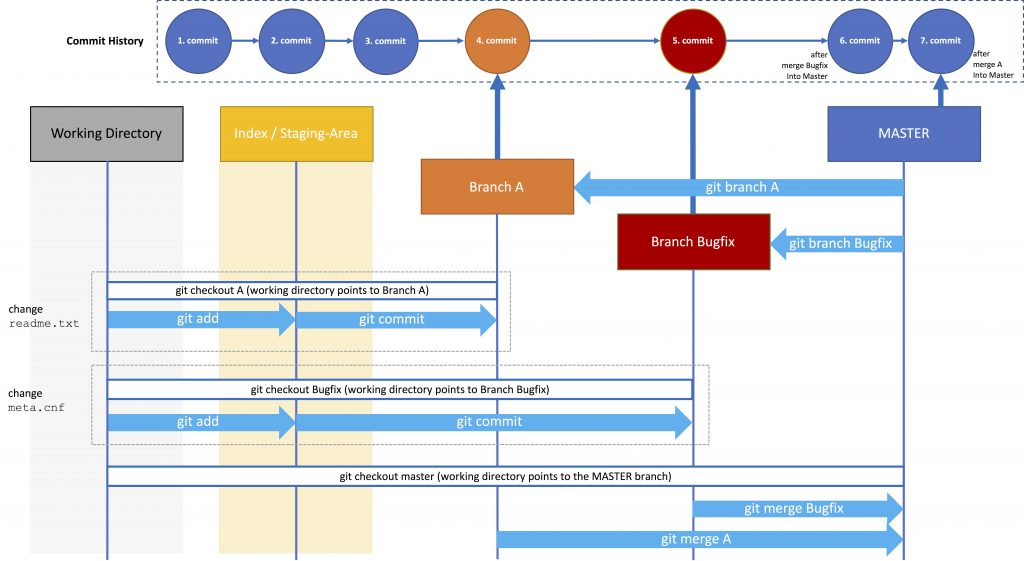
Branching sounds fine, but quite often so-called merge-conflicts occur, even in a single-user local-git-repository environment.
You created a feature branch A to develop a new feature. To implement the new feature you have to add and change a lot of the CSS in styles.css
Suddenly a bug appears on your website. To fix the bug, you also have to make changes in styles.css.
As we learned in the previous part of the tutorial this might not be a problem at all. This is what branching is for. You create a bugfix branch, fix the bug in styles.css, merge it into the MASTER and then deploy the MASTER into production.
So far this is not a problem. The problem will occur when you finished developing your new feature (that also affected styles.css) and merge it into the MASTER. So far changes from the bugfix were only merged with the MASTER. Branch A has no knowledge of this change. With the merge from Branch A into the MASTER, Git doesn’t know which is the correct version. Hence, Git responds with an error: merge-conflict. You have to resolve this conflict manually.
So after merging branch A into the MASTER using git merge A, Git will provide a message like
~/test/gitTest git merge A
error: Merging is not possible because you have unmerged files.
hint: Fix them up in the work tree, and then use 'git add/rm <file>'
hint: as appropriate to mark resolution and make a commit.
fatal: Exiting because of an unresolved conflict.
The whole merge process has put on halt. The data of branch A that was about to be merge is now in the Staging Area of the Master Branch (the Local Repository). You now have to manually resolve the conflict in styles.css manually.
When you edit styles.css you will discover that git added a few lines to the files (the version of styles.css that is currently in the Local Repository (HEAD) and the version with your changes in branch A:
/** Registration page */
.fieldError {
border: 4px solid red;
<<<<<<< HEAD
font-size: 12px;
=======
font-weight: 20;
>>>>>>> A
}
You now have to manually the correct version of styles.css, e.g.
Then you have to add and commit the changes with git commit -a -m "conflict in styles.css resolved"
If you have a look at the Git-commit-history you will recognise that the master has also inherited the whole commit history
commit 31bf689a2f754f8154d66ae776fd80698a7c9174
Merge: 6186303 9c0a9b8
Author: chris <moser.christoph@gmx.de>
Date: Fri Mar 23 12:43:01 2018 +0100
conflict in styles.css resolved
commit 9c0a9b8c37d162207947f2a22e8bdaca89ec39c4
Author: chris <moser.christoph@gmx.de>
Date: Fri Mar 23 12:27:16 2018 +0100
feature A
commit 61863036a5d0f09f52e994be90a04527404f8646
Author: chris <moser.christoph@gmx.de>
Date: Fri Mar 23 12:25:57 2018 +0100
bug fixed in styles.css
...
Remarks
I haven’t covered all the possible things that can happen, e.g. try to make changes in branch A without adding/committing them and check-out the Bugfix branch and other things. Again, before using Git in a serious project, I highly recommend experimenting a bit more with this simple setting (one master, two branches, two text-files) to become more familiar with Git. When you are using Git to develop larger projects, you might have more than one merge-conflict at once. It can be difficult to keep track of all the changes. Hence, in this case, I recommend using Git GUI clients, such as SourceTree and others.
For reasons of simplicity in this tutorial, we will assume that you are working as a single developer with a local repository (MASTER).
Implementing a new Feature
Option 1
When you just add one feature after the other, you can make the changes, add them to the Staging Area and commit the changes to the MASTER as explained in the previous blog post. There is nothing wrong with that when you work alone, one feature after the other.
Option 2
Imagine, you have a version of your software released in production. Then you start working on a new feature. When you are half-way through, you discover that you have a bug in production. If you already transferred files in your staging area (git -add .) you can undo them (git reset), fix the bug, add the affected files (git -add [filename], ...) and commit the changes (git commit -m "bugfix ...").
The disadvantage here is that you carefully have to only add the files affected by the bugfix without adding the files that are affected by the new feature development. It can get even more confusing if the file affected by the bugfix, was already changed when implementing the new, but not yet releasable feature. It will get even more confusing if many developers implement new features or functionality on the same code. But we will cover this later.
Branching
Basic Branching with one Branch
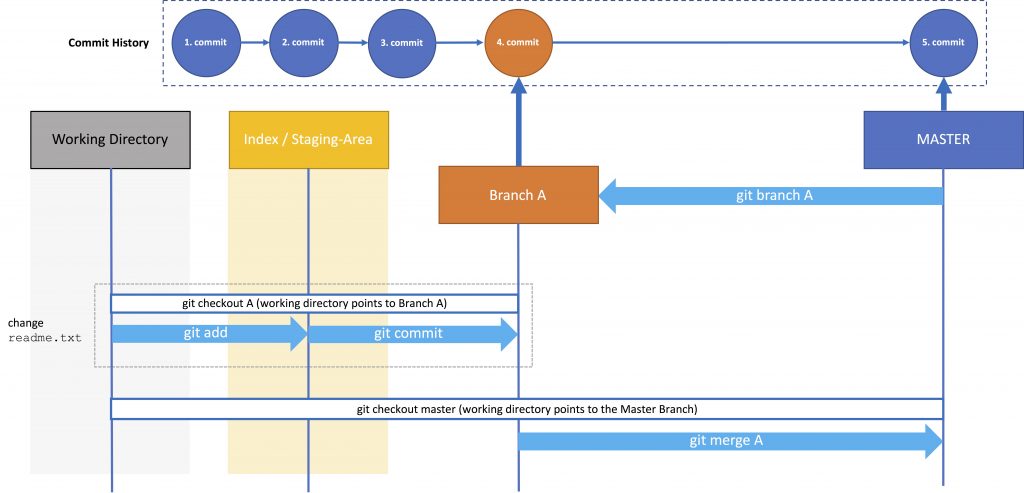
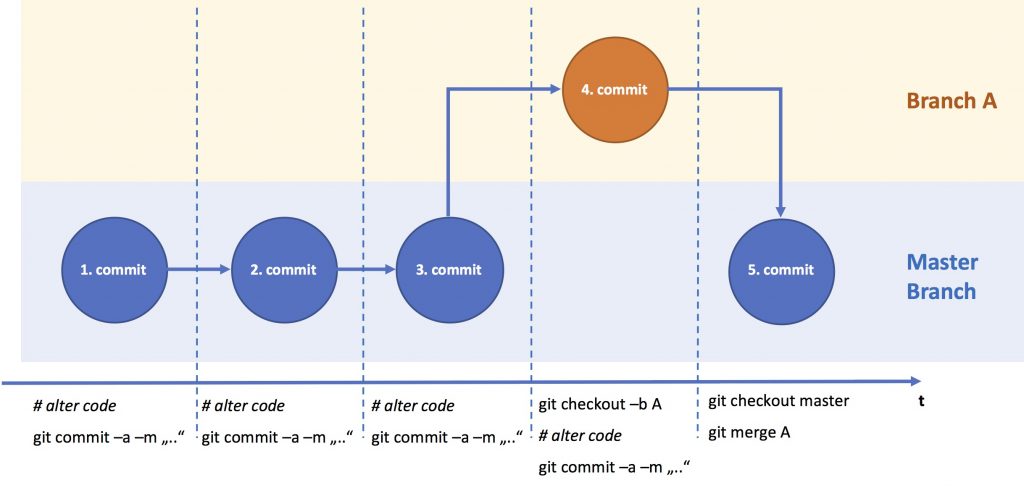
There is a simple clean solution to all the disadvantages mentioned above: branching. Basically branching means, that you branch from the MASTER (your root branch), make your changes in the new branch and subsequently merge your changes back into the MASTER.
# create a new branch
git branch A
# change the branch
git checkout A
#
# make changes in files ...
#
# add all changes to the staging area
git add .
# commit the changes into branch A
git commit -m "implemented feature A"
# checkout the master branch
git checkout master
# merge the changes in branch A to the master
git merge A
You basically create a new branch from the branch you have currently checked-out. Before you switch branches, you usually have to commit the work in the current branch.
git branch [branch-name]
You change branches with
git checkout [branch-name]
You can use the shortcut git checkout -b [branch-name] to create a new branch and check it out. Each branch will inherit the whole commit-history of the branch it derived from, including all tags. You can check this with git log.
The branch you switch to will look like after your last commitment to that branch, e.g. when you create a branch A from the MASTER, switch to it, make changes and commit these changes to A, and then switch back to the MASTER branch, you won’t see these changes yet (until you merge them).
You basically merge into the branch you have currently checked-out or you define a source and destination branch:
git merge also merges the commit history if the branch that was merged and git merge also performs a commit on the destination branch (or the branch you call the merge from). Again, you can check this by using git log.
To show all branches and their commits use
git show-branch
To compare two branches use
git diff [branch-name 1] [branch-name 2]
When you don’t need a branch anymore you can delete it using
git branch -d [branch-name]
You can usually only delete branches that are merged into another branch because otherwise your changes will be lost. You can, of course, force a delete by using
git branch -D [branch-name]
Basic branching with two Branches
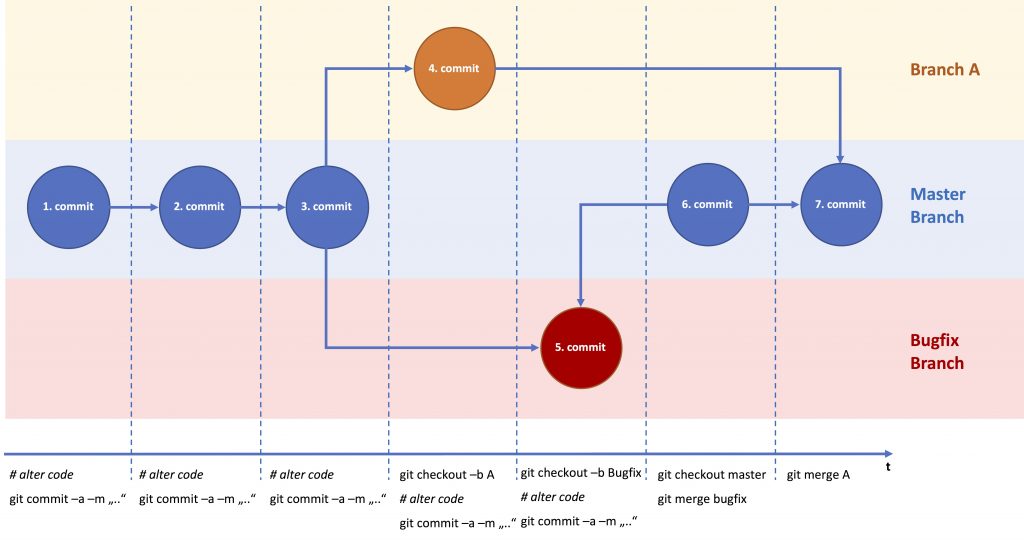
Now imagine the example above where you create a new feature branch to develop a new feature. Then a bug occurs in production. Hence, you create a new branch to fix the bug. Notice, that we are changes two separate files in each branch.
# create a new branch
git branch A
# change the branch
git checkout A
#
# make changes in branch A ...
#
# add all changes to the staging area auf branch A
git add .
# commit the changes into branch A
git commit -m "partly implemented feature A"
# checkout the master branch
git checkout master
# create and checkout Bugfix branch
git checkou -b bugfix
#
# make changes in branch Bugfix ...
#
# add all changes to the staging area auf Bugfix branch
git add .
# commit the changes into the Bugfix branch
git commit -m "fixed bug B in production"
# checkout the master branch
git checkout master
# merge the changes in branch A to the master
git merge Bugfix
Git Basic Branching (2 Branches)
Git Basic Branching Commit View (2 Branches)
As you can see, Branch A is not affected by the changes made on the Bugfix branch or the master branch. You can now checkout branch A again (git checkout A) to continue working on your feature A and merge the changes into the MASTER when you are finished.
Remarks
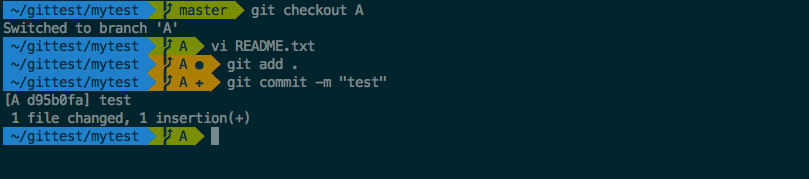
If you are using the git-Plugin in zsh (or something similar for other command shells) you can see of what branch you are in and what status the branch has (see image below). In addition the git-Plugin also provides aliases for most git-commands.
Again, before using Git in a serious project, I suggest experimenting with branches in a simple setting (one master, two branches, two text-files) to become more familiar with Git.
In the next part, we will discover merge-conflict. What happens if you made changes in the same file and then merging it one by one into the master.
I will explain how to connect to set-up and connect to a remote repository (Bitbucket and GitHub) and how to work with these repositories. I don’t want to complicate things, hence this tutorial gives you the basic understanding of how to work with Git. Before you start, you need to generate a SSH key-pair. In the following, I will explain how to set-up a repository at Bitbucket or GitHub. You only need one remote repository, either at Bitbucket or GitHub. Both providers offer free repositories. I prefer BitBucket as it offers free private repositories, which means that no other person can access my code. Nevertheless, you can change your repositories at any time.
Setting up a Bitbucket Repository
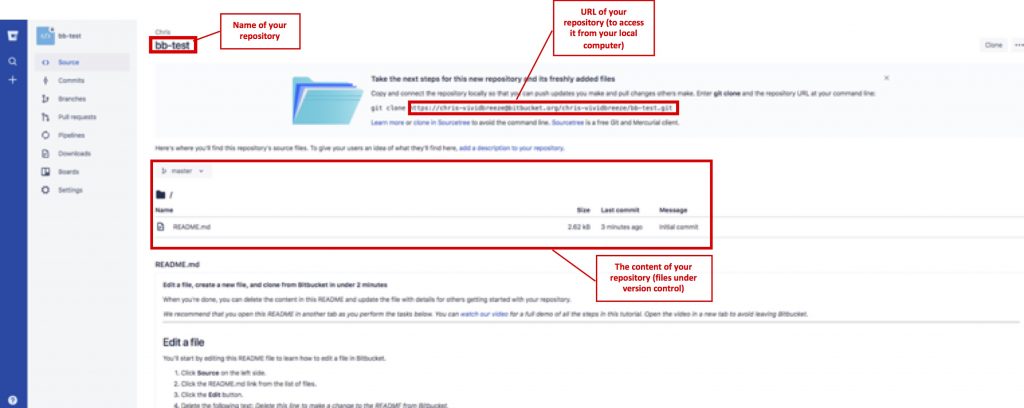
Bitbucket from Atlassian offers unlimited private repositories and up to 5 users for free. First, you have to create a Bitbucket account. At some point, you will be asked if you are „Flying solo?“ or „Plan to work with others?“. For this tutorial please choose the first. Next, I am asked to create a repository. I chose the name bb-test in this tutorial. Choose the default-options. Once your repository is created, you should see something like this.
After creating you see nothing more but an empty folder containing a README.md file. To access your Bitbucket repository you need to deposit your private key. Go to Settings → Access Key and choose Add Key. Copy your private key into your clipboard
cat ~/.ssh/id_rsa.pub | pbcopy
and then copy it into the Key-Textfield. As a label, you can add a name like „Chris‘ Dev Environment“ or similar (if you deposit more than one key, it helps you to distinguish them, e.g. when more people access this private repository). Below I will explain how to access this remote repository.
Setting up a GitHub Repository
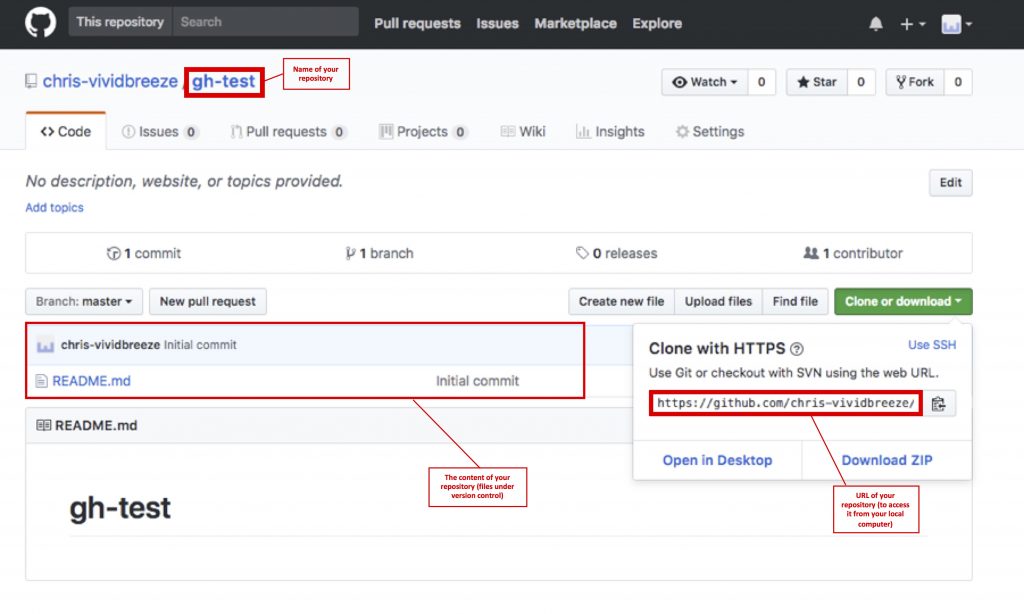
GitHub provides unlimited free repositories for unlimited users, however, all repositories are public. That means anyone has read-access to your repository. If you want to have a private repository you have to get a paid account. Again, please set-up an account first. After a few steps, you are asked to for the name of your new repository. I chose the name gh-test in this tutorial. Also, check the box „Initialize this repository with a README“ which automatically creates a README.md in your repository.
To access your GitHub repository you need to deposit your private key. Go to Settings → Deploy key and select Add deploy key. Copy your private key into your clipboard
cat ~/.ssh/id_rsa.pub | pbcopy
and then copy it into the Key-Textfield. As a label, you can add a name like „Chris‘ Dev Environment“ or similar (if you deposit more than one key, it helps you to distinguish them, e.g. when more people access this private repository). Check Allow write access as we also want to push our code into this repository. Below I will explain how to access this remote repository.
Cloning a remote repository
Once you have created a remote repository you want to access it from your computer. You do this by cloning the remote repository using git clone with the URL (see images above) of your remote repositories. Go to an empty directory and use either:
As your free Bitbucket account can be a private repository, you have to enter your Bitbucket password (not the passphrase of your private key). The free access to GitHub offers only a public repository, so anyone can clone it without using a password.
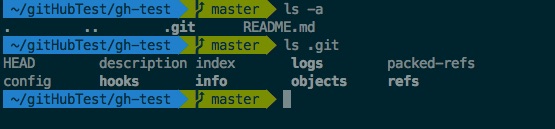
Basically, git clone calls git init before it copies the files from the remote directory. Thus, you should now find a copy of your remote repository on your local computer. In the directory, you can also see a .git, which is a directory that contains the git-configuration. If you are using the git-Plugin in zsh (or something similar for other command shells) you should see something like this:
Alternatively, you can connect to a git Repository by the Git protocol (with no authentication) or via ssh:
When you used git clone, your local repository will automatically point to the remote URL is was cloned from. Hence you don’t always have to enter the URL when you push contents from the local to the remote repository. You can also add the remote repository to your local git config with
First, you should learn how to use git with local repositories to understand the basics. After you cloned the remote repository, changes will only be made on your local copy of the remote repository (so far). This means you are working with two independent repositories: the remote repository on the remote server and your local repository on your computer. This is contrary to SVN where there is a strong relationship between the remote repository and the working copy. This is why Git is called a distributed version control system.
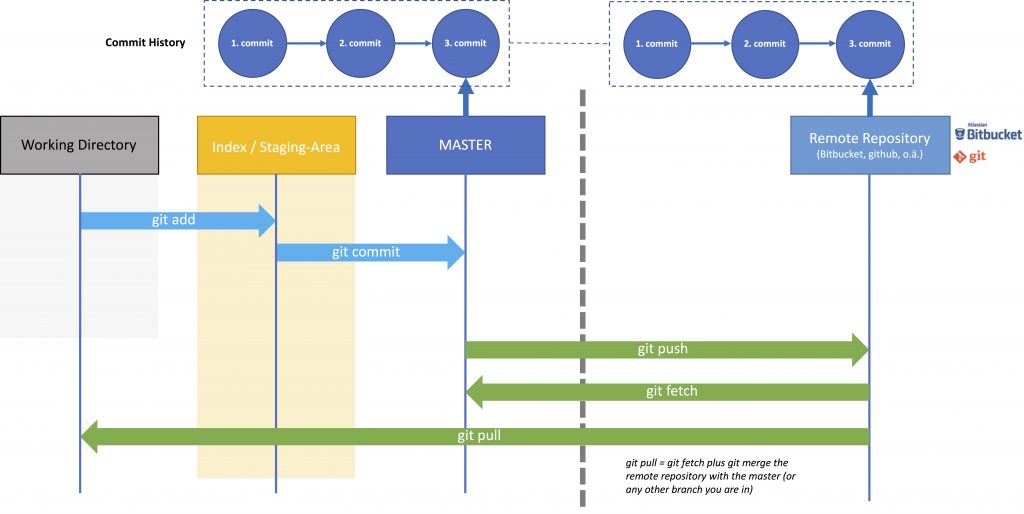
To work with remote repositories, you mostly will use git push, git pull or git fetch.
With git fetch you only copy the remote branch to the Local repository, it doesn’t update your Working Branch.
With git pull you pull the remote branch and merge the contents to your current branch, i.e. you update your local branch with the remote version. git pull is basically a git fetch with a subsequent git merge. So if you Working Directory references to the Master branch (git checkout master), the Master branch will be updated. If it references a branch A (git checkout A), branch A will be updated.
With git push you push your current local branch to your remote repository, i.e. you update the remote branch with the changes you made locally. You can also push a local branch to a remote-repository by using
To delete a branch from the remote repository (e.g. after you made your changes and merged your branch into the master branch) use
git push origin --delete [branch-name]
This image shows the interaction between the remote repository, the local repository (in this case the Master) and the Working Directory.
Git Remote Workflow
Remarks
I recommend to get an account at Bitbucket or GitHub and experiment with Git before you are using it real projects. It sometimes can get a bit confusing to work with remote and local repositories, with remote and local branches etc. However, it’s important to understand these basics before working with others. In one of the next posts, I will take a look at different collaboration strategies.
where data is transferred over a secure channel. This means that all data transmitted in both directions is secure from eavesdropping. In software development it is used to securely connect to a remote git repository, a test- and production server etc. A SSH client should be already installed on a UNIX systems (such as Linux or MacOSX).
The SSH protocol
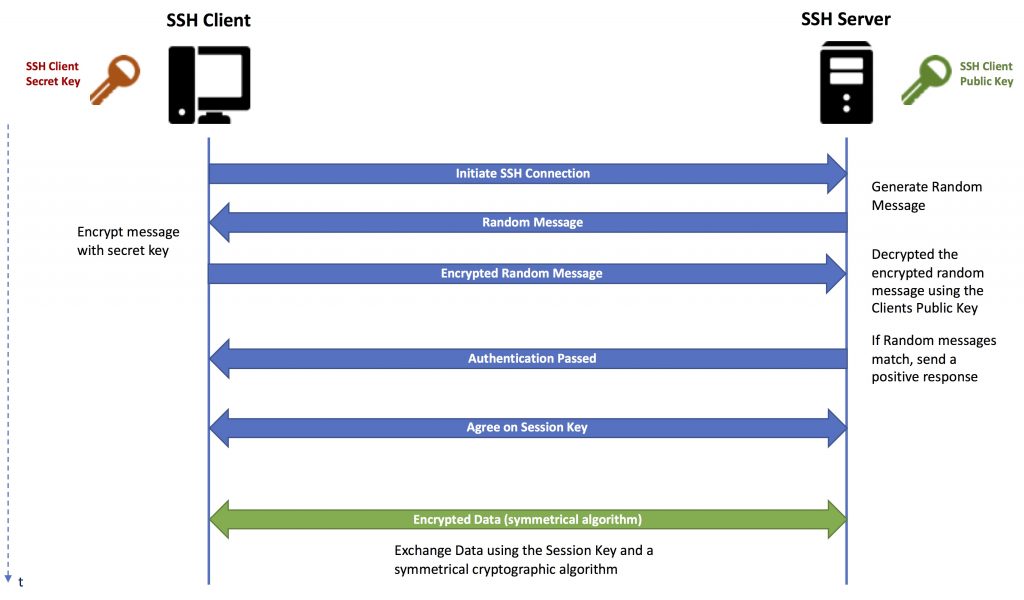
You can use SSH to log into the remote server, transfer files and execute commands. Before you do this, you have generate a key pair on your local computer. SSH uses asymmetrical cryptography (or public-key cryptography). The so called private key (or secret key) is used for encrypting the data, while the public key is used for decryption and vice versa. Hence this key-pair is generated from the same random data. Asymmetrical algorithms are not very fast, compared to symmetrical cryptographic algorithms. Symmetrical algorithms use a single key that is shared between both sides (client and server) to encrypt the transmitted data. Hence, SSH uses public-key cryptography only for authentification (to prove that the client is allowed to access the server) and to exchange a new key (session key) that is used to encrypt and decrypt connection between client and server. Here symmetrical cryptographic is being used. The secret key is stored securely on your computer and should be never ever given to anyone else. The public key is be distributed publicly, e.g. to the remote server you want to access.
This image shows asimplified version of the SSH protocol with client authentification (usually client and server agree on the encryption algorithms and other parameter, Diffie-Hellman is used for session key generation and exchange and more). However, this simplification should be sufficient to understand the basics you need to know as a software developer.
Generating SSH Keys
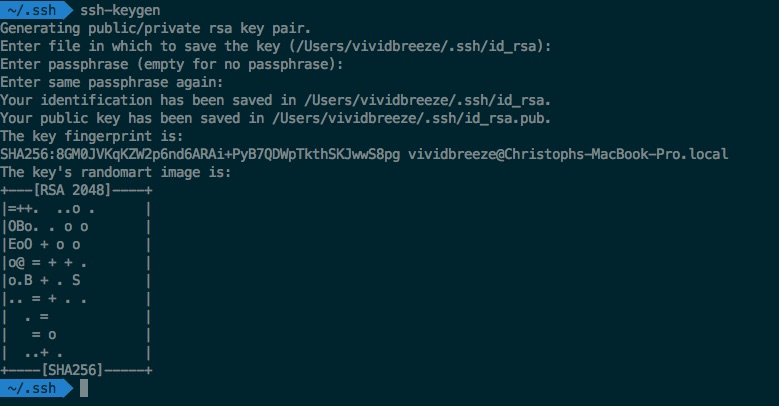
First check if you haven’t already generated a SSH key-pair by looking into the .ssh folder in your home directory
ls ~/.ssh
If the directory is not present or doesn’t contain something like: id_rsa, id_rsa.pub you need to generate a new key-pair by using
ssh-keygen
You are being ask for the key-store directory and a passphrase (a password which can also contain spaces). I did not use any special algorithms here, so in my case RSA with a key-length of 2048 bit was used (which is considered to be a sufficient key-length for a strong security). In the image below you might notice the SHA-256 and fingerprint. SHA256 is a so called hash-function, A hash-function is a one-way function which calculates a fixed-length value (hash-value) out of a arbitrary sized data. One-way means that you can’t re-create the original message from the hash-value. The result is often called a fingerprint (a compressed value of my key in this case).
If you want to use other cryptographic algorithms, you can do so by using the -t option, e.g. if you want to use DSA
ssh-keygen -t dsa
to change the key-length, use the -b parameter
ssh-keygen -t rsa -b 4096
The keys (id_rsa, id_rsa.pub) should now be visible in the ~/.ssh directory. The secret key (id_rsa) is protected by the pass-phrase. You can upload the public key (id_rsa.pub) to the remote server or service you want to connect with, e.g. a git-Repository. If you have root access to the remote server you have to store the public key in.~/.ssh/authorized_keys.
You can also let ssh-keygen in a script without the need of a pass-phrase
Git is a distributed version control system. Distributed means, that each user has a local copy of a (remote) repository on his or her computer. I will dive right into Git using hands-on examples. In this part, I will only focus on local repositories to explain the basics. There are many ways to install git. On MacOSX I prefer using brew:
brew install git
Setting Up a Local Repository
A git repository contains a history of files in your working directory (the directory that is under version control). To put a local directory under version control go into the directory and enter
git -init
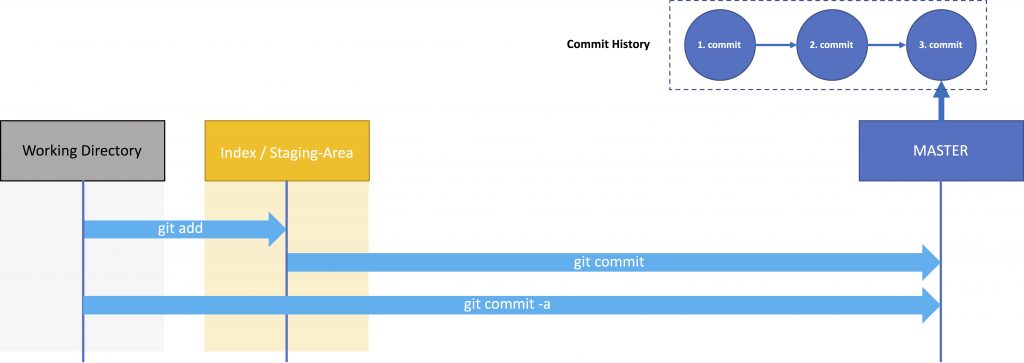
Now this directory is your Working Directory and the Local Repository was created. If there already are files in the Working Directory they are not yet under version control. You will have to add them first by using
git -add .
Git Basic Workflow
With git-add ., the files are initially put in Staging Area (see image above), also called Index. The Staging Area is a container that holds all files about to be committed. You can add single files with git-add [filename].
If you accidentally put files in your Staging Area you can remove them usegit reset (without the dot, to remove all staged files) or git reset [filename] to remove a specific file.
To put the files from the Index to the Local Repository use
git commit -m “[commit message]”
You can also combine both commands by using
git commit -a -m "[commit message]"
The commit message is a message that describes the reason for the commit, e.g. „bug xyz fixed“ or „user story #xyz“. It’s kind of like the name for the container, which holds the collection of files you committed. Each commit creates an entry into the commit history. You can list the commit history with: git log or git log --pretty=oneline for a more compact version.
[expand title=“Why don’t you commit each file separately, why is there a Staging Area?“]
In general, when you add a new feature to your software, you have to add and/or change more than one files. Just imagine you want to display the gender as a new field on your website. If this data is not available in the database, you might have to change some .java, .css, .js and other files. You put all these changes together in the Staging area and commit it. The commit history (git log) is clean and clear. Later you will see that you can set the working directory to a previous commit or see the changes you have made. If in contrast, you would commit each file separately, the context (display gender on your webpage) would be lost. In addition, the commit history would be confusing. This might sound simple now, but in a real project, you would work with other team members and the same data, which would make it even more confusing.
[/expand]
[expand title=“What is this HEAD?“]
As we haven’t discussed branches yet, the HEAD basically points to the latest commit in the MASTER (this is not 100% accurate but it gives you a picture).
[/expand]
To get a status of the files (untracked files that are not under version control, files that have changed but have not been added, files in the Index that haven’t been committed) use
git status
Tagging
When you perform a git log you will notice that the commit names or references seem very cryptic, e.g.
commit 2a21b89d44a877b1d5892ef9f12cc89bd0a871f6
Author: chris <moser.christoph@gmx.de>
Date: Tue Mar 20 15:39:16 2018 +0100
2. Change to Master
commit dadbf09b4e94c72901f68e65d1440930418eee95
Author:chris <moser.christoph@gmx.de>
Date: Tue Mar 20 15:38:51 2018 +0100
1. Change to Master
Maybe later you want to switch back to an earlier commit or want to see the differences between the current state and an earlier state of your software in Git. With tagging, you can give important versions of your software a name, e.g. you want to release the current version of your Working Directory in production (-a = name (tag), -m = comment)
git tag -a v1.0 -m "First Release of your software"
You can list all tags using git tag or git log --decorate. For more detailed information use git show [tag-name].
The tag we created before is a so-called annotated tag. You can also use lightweight tags. These tags don’t contain much more information than a checksum (no author, comment, changes etc.).
git tag v1.0.1
If you want to switch to an earlier version of your code use
git checkout [tag-name]
If you use this command, Git will go into the so-called “detached HEAD” state (the HEAD is not pointing to the latest commit but to an earlier commit). There are ways to change earlier versions of your code, but I do not recommend it and hence will not go into detail here. I only recommend using it to look into an earlier version of your code or to deploy an older version of your software.
With git checkout master you can get back to the latest commit to work as usual.
If you want to see the differences between two versions use
git diff [tag-name 1] [tag-name 2]
or if you want to compare an earlier version with the current version use
git diff [tag-name] master
When you have lots of changes (which is the common case), you will use a graphical git-client, as diffs are displayed more structured.
Configuration
git config offers options to configure your git repository. Most settings can be applied global (parameter --global) or to your local (current) repository (parameter --local)
Change the author in the commit-history in all repositories with: git config --global user.name [name]
Change the author in the commit-history in your current local repository with: git config --local user.email [email]
You just learned the basics here. I highly recommend experimenting a bit with the command line interface to become more familiar more familiar with Git. Also, have a look at the man pages to use the commands with other parameters. As people learn differently, I also suggest reading other literature than this blog post.
This article outlines how to install my preferred development environment using iTerm2 and zsh (Z shell) together with some plugins on MacOSX. It doesn’t go into much detail and describes a hands-on installation of these tools.