I highly recommend reading all my Hackintosh posts (and consult other tutorials) before you actually decide to build a Hackintosh. It is a rather tedious task. It might run straight-away. However, in my case – and also in the tutorials, I found on the Internet – it can frustrating at times. When I put into account the hours I spent building an experimental Hackintosh, it might have been less expensive buying an actual Mac from Apple. In addition, with every update, Apple releases you have to put in some extra work.
I use my 13″ MacBook Pro from 2016 (the first one with the touch bar) for software development. It is equipped with 16 GB of RAM and a Dual-Core i5. It has decent performance but still is a bit on the slow side. And with three VMs I’m using I had some serious crashes. Additionally, I mostly use in my home office – so I don’t need the portability of a notebook.
So what are the alternatives – and Apple iMac or iMac Pro? Both come with a built-in screen and I have an external monitor. An Apple Mac Pro? It is far too expensive. An Apple Mac mini? Too expensive and not up to date.
So recently my attention was drawn to some videos about a Hackintosh. I did some more research and to me, it seemed that these days it’s fairly easy to build one from PC hardware, especially if you stick with the hardware used in Apple computers.
Which Hardware did I choose?
I found compatible hardware on tonymacx86’s page and bought the following hardware – I wanted to have a small powerful computer. I know that I could have used other hardware, e.g. an AMD Rizen with more parallel threads which might be more suitable for software development. However, my goal was to have a Hackintosh with as less trouble as possible in the future, so I stuck with the hardware Apple supports.
While installing the Software I learned that the WLAN / Bluetooth chip on the Gigabyte Z390 is not compatible with Mac OSX. In this case I could either exchange the chip with a Broadcom chipset or, as I am to tired to disabled the whole mainboard again, I went for a Bluetooth dongle and WLAN dongle as a temporary solution.
The assembly was pretty straightforward – with only minor annoyances. I used some videos from YouTube and the manuals. The DAN case is super-small but so extremely well organised that (almost) everything fits just perfectly. I assembled the parts in this particular order to avoid too much hassle (you only need a Philips screwdriver).
Motherboard
CPU (remove the plastic part und insert the CPU)
RAM
SSD (it’s under a heat sink)
CPU Cooler
Case (remove the side parts and the top part)
Connector blend (attach it in the back of the case)
Motherboard (attach it in the case)
Power Supply (and connect it with the motherboard)
Short Test with the Internal graphics card (check the bios settings if all the hardware appears)
Graphics card (in the riser slot and connect it with the power supply)
These videos helped me. I highly recommend watching these videos before you assemble the hardware
The aim of this tutorial is to provision Artifactory stack in Docker on a Virtual Machine using Ansible for the provisioning. I separated the different concerns so that they can be tested, changed and run separately. Hence, I recommend you run the parts separately, as I explain them here, in case you run into some problems.
Prerequisites
On my machine, I created a directory artifactory-install. I will later push this folder to a git repository. The directory structure inside of this folder will look like this.
Please create the subfolders artifactory(the folder that we will copy to our VM) and nginx-config subfolder (which contains the nginx-configuration for the reverse-proxy as well as the certificate and key).
Installing a Virtual Machine with Vagrant
I use the following Vagrantfile. The details are explained in Vagrant in a Nutshell. You might want to experiment with the virtual box parameters.
agrant.configure("2") do |config|
config.vm.define "artifactory" do |web|
# Resources for this machine
web.vm.provider "virtualbox" do |vb|
vb.memory = "2048"
vb.cpus = "1"
end
web.vm.box = "ubuntu/xenial64"
web.vm.hostname = "artifactory"
# Define public network. If not present, Vagrant will ask.
web.vm.network "public_network", bridge: "en0: Wi-Fi (AirPort)"
# Disable vagrant ssh and log into machine by ssh
web.vm.provision "file", source: "~/.ssh/id_rsa.pub", destination: "~/.ssh/authorized_keys"
# Install Python to be able to provision machine using Ansible
web.vm.provision "shell", inline: "which python || sudo apt -y install python"
end
end
Installing Docker
As Artifactory will run as a Docker container, we have to install the docker environment first. In my Playbook (docker.yml), I use the Ansible Role to install Docker and docker-compose from Jeff Geerling. The role variables are explained in the README.md. You might have to adopt this yaml-file, e.g. defining different users etc.
As we will see later, the magic happens in the ~/artifactory folder on the VM. So first we will clean-up a previous installation, e.g. stopping and removing the running containers. There are different ways to achieve this. I will use a docker-compose down, which will terminate without an error, even if no container is running. In addition, I will delete the artifactory-folder with all subfolders (if they are present).
Copy nginx-Configuration and docker-compose.yml
The artifactory-folder includes the docker-compose.yml to install the Artifactory stack (see below) and the nginx-configuration(see below). They will be copied in a directory with the same name to the remote host.
I will use nginx as a reverse-proxy that also allows a secure connection. The configuration-file is static and located in the nginx-config subfolder (reverse_proxy_ssl.conf)
The configuration is described in the nginx-docs. You might have to adopt this file for your needs.
The proxy_pass is set to the service-name inside of the Docker overlay-network (as defined in the docker-compose.yml). I will open port 443 for an SSL connection and 8080 for a non-SSL connection.
Create a Self-Signed Certificate
We will create a self-signed certificate on the remote-host inside of the folder nginx-config
The certificate and key are referenced in the reverse_proxy_ssl.conf, as explained above. You might run into problems, that your browser won’t accept this certificate. A Google search might provide some relief.
Run Artifactory
As mentioned above, we will run Artifactory with a reverse-proxy and a PostgreSQL as its datastore.
I am not super satisfied, as out-of-the-box I receive a „Mounted directory must be writable by user ‚artifactory‘ (id 1030)“ error when I bind /var/opt/jfrog/artifactory inside of the container to the folder ./data/artifactory on the VM. Inside of the Dockerfile for this image, they use a few tasks with a user „artifactory“. I don’t have such a user on my VM (and don’t want to create one). A workaround seems to be to set the user-id and group-id inside of the docker-compose.yml as described here.
Alternatively, you can use the Artifactory Docker image from Matt Grüter provided on DockerHub. However, it doesn’t work with PostgreSQL out-of-the-box and you have to use the internal database of Artifactory (Derby). In addition, the latest image from Matt is built on version 3.9.2 (the current version is 6.2.0, 18/08/2018). Hence, you have to build a new image and upload it to your own repository. Sure if we use docker-compose to deploy our services, we could add a build-segment in the docker-compose.yml. But if we use docker stack to run our services, the build-part will be ignored.
I do not publish a port (default is 8081) as I want users to access Artifactory only by the reverse-proxy.
PostgreSQL
I use the official PostgreSQL Docker image from DockerHub. The data-volume inside of the container will be bound to the postgresql folder in ~/artifactory/data/postgresql on the VM. The credentials have to match the credentials for the artifactory-service. I don’t publish a port, as I don’t want to use the database outside of the Docker container.
The benefits of using a separate database are when you have intensive usage or a high load on your database, as the embedded database (Derby) might then slow things down.
Nginx
I use Nginx as described above. The custom configuration in ~/artifactory/nginx-config/reverse_proxy_ssl.conf is bound to /etc/nginx/conf.d inside of the Docker container. I publish port 443 (SSL) and 8080 (non-SSL) to the world outside of the Docker container.
Summary
To get the whole thing started, you have to
Create a VM (or have some physical or virtual machine where you want to install Artifactory) with Python (as needed by Ansible)
Register the VM in the Ansible Inventory (/etc/ansible/hosts)
Start the Ansible Playbook docker.yml to install Docker on the VM (as a prerequisite to run Artifactory)
Start the Ansible Playbook artifactory.yml to install Artifactory (plus PostgreSQL and a reverse-proxy).
I recommend adopting the different parts for your needs. I am sure you could also improve a lot. Of course, you can include the Ansible Playbooks (docker.yml and artifactory.yml) directly in the provision-part of your Vagrantfile. In this case, you have to only run vagrant up.
Integrating Artifactory with Maven
This article describes how to configure Maven with Artifactory. In my case, the automatic generation of the settings.xml in ~/.m2/ for Maven didn’t include the encrypted password. You can retrieve the encrypted password, as described here. Make sure you update your Custom Base URL in the General Settings, as it will be used to generate the settings.xml.
Possible Error: Broken Pipe
I ran into an authentification problem when I first tried to deploy a snapshot archive from my project to Artifactory. It appeared when I ran mvn deploy as (use -X parameter for a more verbose output)
Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact com.vividbreeze.springboot.rest:demo:jar:0.0.1-20180818.082818-1 from/to central (http://artifactory.intern.vividbreeze.com:8080/artifactory/ext-release-local): Broken pipe (Write failed)
A broken pipe can mean everything, and you will find a lot when you google it. A closer look in the access.log on the VM running Artifactory revealed an
2018-08-18 08:28:19,165 [DENIED LOGIN] for chris/192.168.0.5.
The reason was that I provided a wrong encrypted password (see above) in ~/.m2/settings. You should be aware, that the encrypted password changes everytime you deploy a new version of Artifactory.
Possible Error: Request Entity Too Large
Another error I ran into when I deployed a very large jar (this can happen with Spring Boot apps that carry a lot of luggage): Return code is: 413, ReasonPhrase: Request Entity Too Large.
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:2.8.2:deploy (default-deploy) on project demo: Failed to deploy artifacts: Could not transfer artifact com.vividbreeze.springboot.rest:demo:jar:0.0.1-20180819.092431-3 from/to snapshots (http://artifactory.intern.vividbreeze.com:8080/artifactory/libs-snapshot): Failed to transfer file: http://artifactory.intern.vividbreeze.com:8080/artifactory/libs-snapshot/com/vividbreeze/springboot/rest/demo/0.0.1-SNAPSHOT/demo-0.0.1-20180819.092431-3.jar. Return code is: 413, ReasonPhrase: Request Entity Too Large. -> [Help 1]
I wasn’t able to find anything in the Artifactory logs, nor the STDIN/ERR of the nginx-container. However, I assumed that there might a limit on the maximum request body size. As the was over 20M large, I added the following line to the ~/artifactory/nginx-config/reverse_proxy_ssl.conf:
server {
...
client_max_body_size 30M;
...
}
Further Remarks
So basically you have to run three scripts, to run Artifactory on a VM. Of course, you can add the two playbooks to the provision-part of the Vagrantfile. For the sake of better debugging (something will go probably wrong), I recommend running them separately.
The set-up here is for a local or small team installation of Artifactory, as Vagrant and docker-compose are tools made for development. However, I added a deploy-part in the docker-compose.yml, so you can easily set up a swarm and run the docker-compose.yml with docker stack without any problems. Instead of Vagrant, you can use Terraform or Apache Mesos or other tools to build an infrastructure in production.
As we have seen in the tutorial about Docker swarm, the IP addresses of our services can change, e.g. every time we deploy new services to a swarm or containers are restarted or newly created by the swarm-manager etc. So services better address other services by using their name instead of their IP-address.
Default Overlay Network
As we have seen in the Docker Swarm Tutorial, an application can span several nodes (physical and virtual machines) that contain services that communicate with each other. To allow services to communicate with each other, Docker provides so-called overlay networks.
Creating network dataapp_default
Creating service dataapp_web
Now let us show all the networks with the scope on a swarm
docker network ls
NETWORK ID NAME DRIVER SCOPE
515f5972c61a bridge bridge local
uvbm629gioga dataapp_default overlay swarm
a40cd6f03e65 docker_gwbridge bridge local
c789c6be4aca host host local
p5a03bvnf92t ingress overlay swarm
efe5622e25bf none null local
If a container joins a swarm, two networks are created on the host the container runs on
ingress network, as the default overlay-network. This network will route requests for services to a task for that service. You can find more about ingress filtering on wikipedia.
docker_gwbrige, which connects stand-alone Docker containers (like the two alpine containers we created earlier) to containers inside of a swarm.
You can specify a user-defined overlay network in the docker-compose.yml. We haven’t done this so far, so Docker creates one for use with the name of the service and an extension, in this case, dataservice_default.
Let us verify which containers belong to our network dataservice_default.
docker-machine ssh vm-manager docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
99e248ad51bc vividbreeze/docker-tutorial:version1 "java DataService" 19 minutes ago Up 19 minutes dataapp_dataservice.1.osci7tq58ag6o444ymldv6usm
f12dea1973da vividbreeze/docker-tutorial:version1 "java DataService" 19 minutes ago Up 19 minutes dataapp_dataservice.3.2m6674gdu8mndivpio008ylf5
We see that two containers of our service are running on the vm-manager. Let us now have a look at the dataservice_default network on the vm-manager
In the Containers-section of the REST response, you will see three containers that belong to the dataservice_default network, the two containers above, as well as a default-endpoint. You can verify vm-worker1 on your own.
User-Defined Overlay Network
So far our application consists of only one service. Let us add another service to our application (a database). In addition, we define our own network.
We added a database service (a Redis in-memory data storage service). In addition, we defined a network (data-network) and added both services to this network. You will also see a constraint for the Redis service, which defines that it should only run on the vm-manager. Now let us deploy our altered service
Creating network dataapp_data-network
Creating service dataapp_dataservice
Creating service dataapp_redis
As expected, the new network (dataapp_data-network) and the new service (dataapp_redis) were created, our existing service was updated.
docker network ls -f "scope=swarm"
NETWORK ID NAME DRIVER SCOPE
dobw7ifw63fo dataapp_data-network overlay swarm
uvbm629gioga dataapp_default overlay swarm
p5a03bvnf92t ingress overlay swarm
The network is listed in our list of available networks (notice that the dataapp_default network still exists. As we don’t need it anymore and can delete it with
docker network rm dataservice_default
Let us now log into our containers and see if we could ping the other containers using their name. First get a list of containers on vm-worker1 (the container ids are sufficient here)
docker-machine ssh vm-worker1 docker container ls -q
cf7fd10d88be
9ea79f754419
6cd939350f74
Now let us execute a ping to the service dataservice and to the redisservice that runs on the vm-manager from one of these containers.
PING web (10.0.2.6) 56(84) bytes of data.
64 bytes from 10.0.2.6: icmp_seq=1 ttl=64 time=0.076 ms
64 bytes from 10.0.2.6: icmp_seq=2 ttl=64 time=0.064 ms
PING redis (10.0.2.4) 56(84) bytes of data.
64 bytes from 10.0.2.4: icmp_seq=1 ttl=64 time=0.082 ms
64 bytes from 10.0.2.4: icmp_seq=2 ttl=64 time=0.070 ms
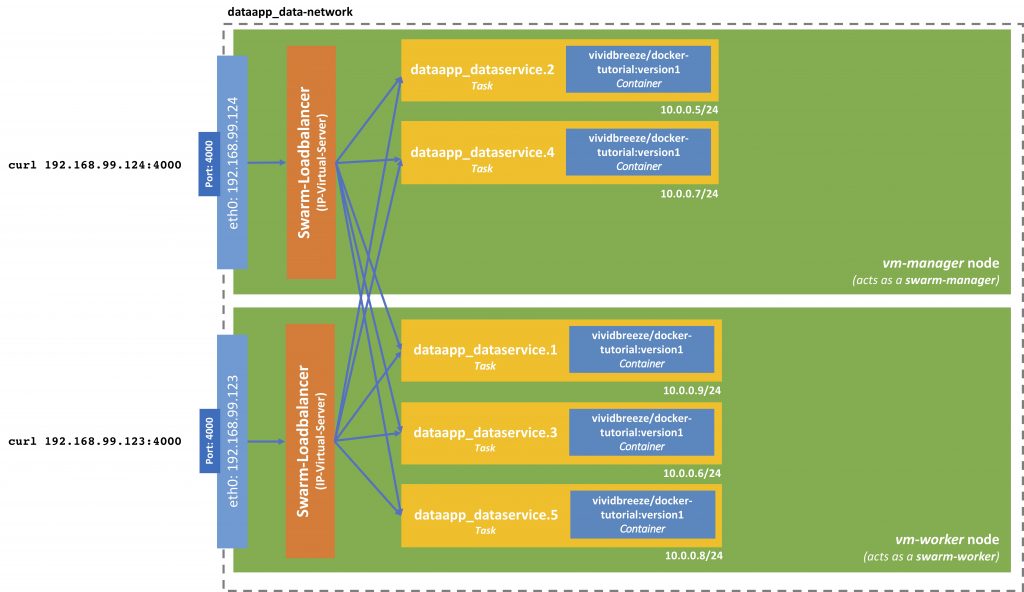
Routing Mesh
The nodes in our swarm now the IP-address 192.168.99.124 (vm-manager) and 192.168.99.123 (vm-worker1)
docker-machine ip vm-manager
docker-machine ip vm-worker1
We can reach our webservice from both(!) machines
curl 192.168.99.124:4000
curl 192.168.99.123:4000
It doesn’t matter if the machine is a manager-node or a worker-mode. Why is this so?
Docker Swarm Ingress Network
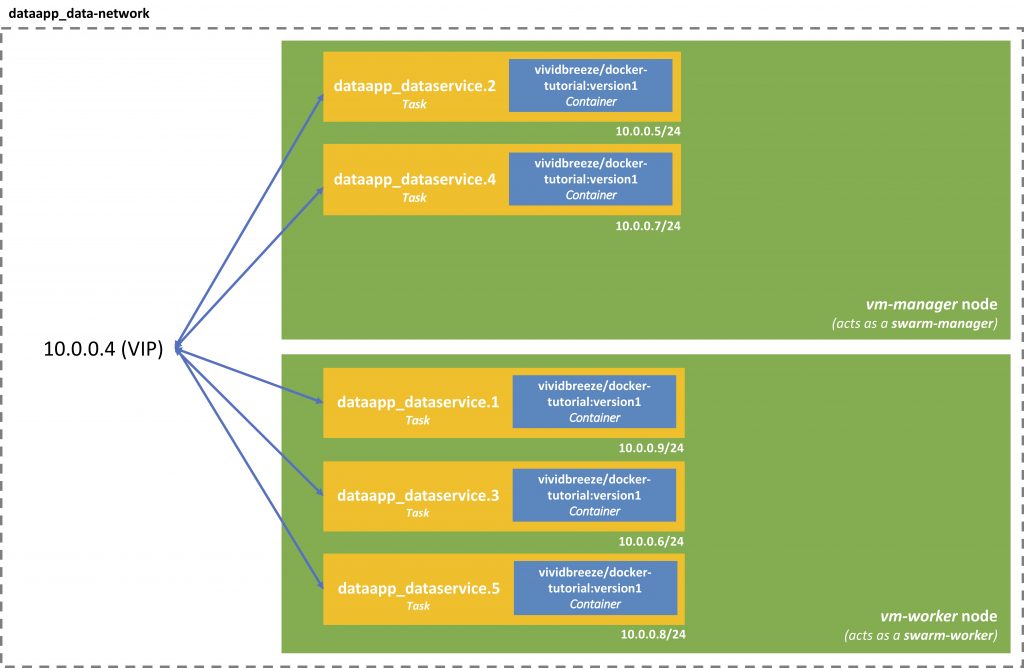
Earlier, I mentioned the so-called ingress network or ingress filtering. This network receives a service request and routes it to the corresponding task. The load-balancing is present on each node and uses the IP virtual server from the Linux kernel. This load-balancer is stateless and routes packages on the TCP-Layer.
Internally the containers communicate via a virtual IP. The beauty here is that if one container/task crashes, the other containers won’t notice, as they communicate with each other via the Virtual IP.
Docker Swarm Inter-Container Communication via Virtual IP
You can find this virtual IP by using
docker service inspect dataapp_dataservice
Further Remarks
Of course, every container can also connect to the outside world. In inherits the DNS settings from the Docker daemon (/etc/hosts and /etc/resolv.conf).
The name service provided by Docker only works within the Docker space, e.g. within a Docker swarm, between containers. From outside of a container, you can’t reference the services by their name. Often this isn’t necessary and even not desired for security reasons (like the Redis datastore in our example). Here you might want to have a closer look at Zookeeper or Consul or similar tools.
However, if you have applications running with many services running, you might consider Docker management tools, such as Portainer, Docker ToolBox, or Dockstation.
Containers, that run on the same machine (share the same Docker daemon) and are not part of a swarm use the so-called bridge network (a virtual network) to communicate with each other.
Let us create two basic containers
docker container run -d --name nginx2 -p3001:80 nginx:alpine
docker container run -d --name nginx2 -p3002:80 nginx:alpine
You can inspect the bridge-network with
docker network inspect bridge
and you will see in the container section of this REST response, that the newly created docker-containers belong to this network.
Now let us see if the nginx-containers can see each other, as well as the bridge.
docker container exec -it nginx1 ping 172.17.0.3
docker container exec -it nginx1 ping 172.17.0.1
docker container exec -it nginx2 ping 172.17.0.2
docker container exec -it nginx2 ping 172.17.0.1
In each case, you should be able to reach the destination
PING 172.17.0.1 (172.17.0.1): 56 data bytes
64 bytes from 172.17.0.1: seq=0 ttl=64 time=0.092 ms
64 bytes from 172.17.0.1: seq=1 ttl=64 time=0.167 ms
64 bytes from 172.17.0.1: seq=2 ttl=64 time=0.126 ms
Default Bridge Network Docker
However, what is not working with the default bridge network is name resolution, e.g.
docker container exec -it nginx1 ping nginx2
should not work and lead to a
ping: bad address 'nginx2'
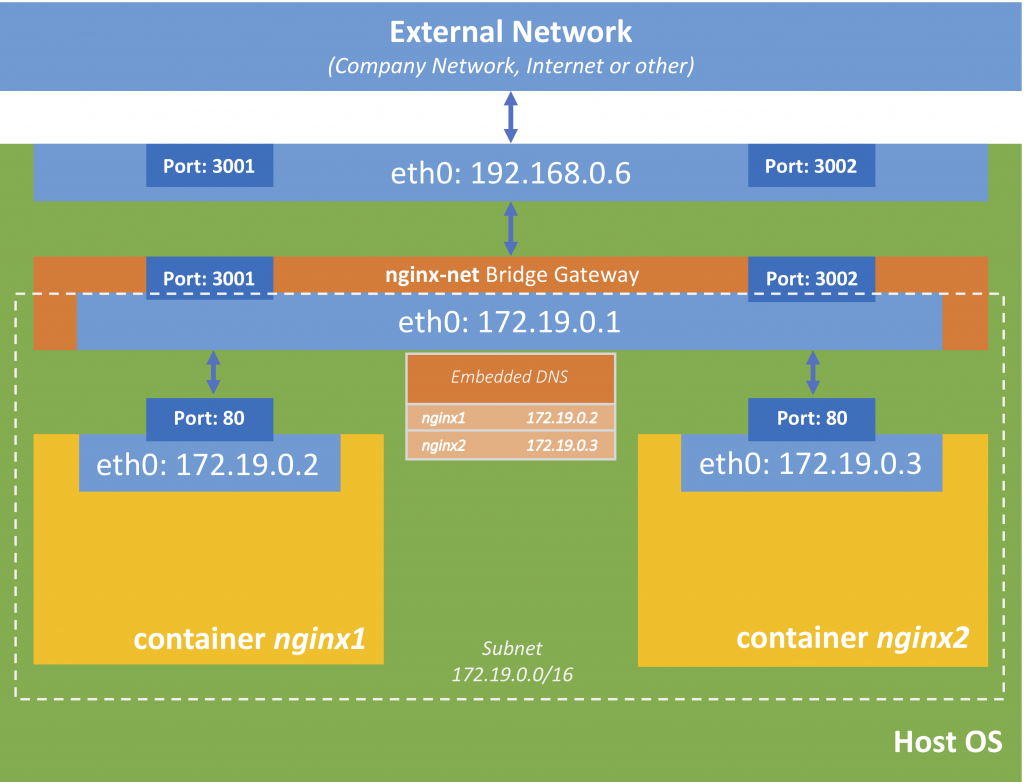
Custom Bridge Networks (embedded DNS)
So to make this work, we have to create our own network
docker network create --driver bridge nginx-net
You can see the new network (and other networks) by using
docker network ls
NETWORK ID NAME DRIVER SCOPE
1f3e6ded4f9a bridge bridge local
20fe2ddb80e6 host host local
6d96ed99b06b nginx-net bridge local
5866618435c1 none null local
Now let us connect our two containers to this network
docker network connect nginx-net nginx1
docker network connect nginx-net nginx2
If you now do a docker network inspect nginx-net you will see that both containers are connected to this network. You will notice, that the IP-addresses of these containers in this network have changed (the subnet is 172.19.0.0/16 compared to 172.17.0.0/16 as in the default-bridge network).
Now let run a ping against the other containers by name again
docker container exec -it nginx1 ping nginx2
PING nginx2 (172.19.0.3): 56 data bytes
64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.139 ms
64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.152 ms
c64 bytes from 172.19.0.3: seq=2 ttl=64 time=0.100 ms
The same should work for the other connections. So basically, the name of the container is its host-name.
Custom Bridge Network Docker
So why is DNS inside of Docker networks so important? As we have especially seen in the tutorials about Docker Swarm, you can’t rely on the IP address of containers, as they may change, especially when a swarm manager has control over the containers. Hence it is much reliable and easier to reference containers by name than their IP address.
Round-Robin DNS
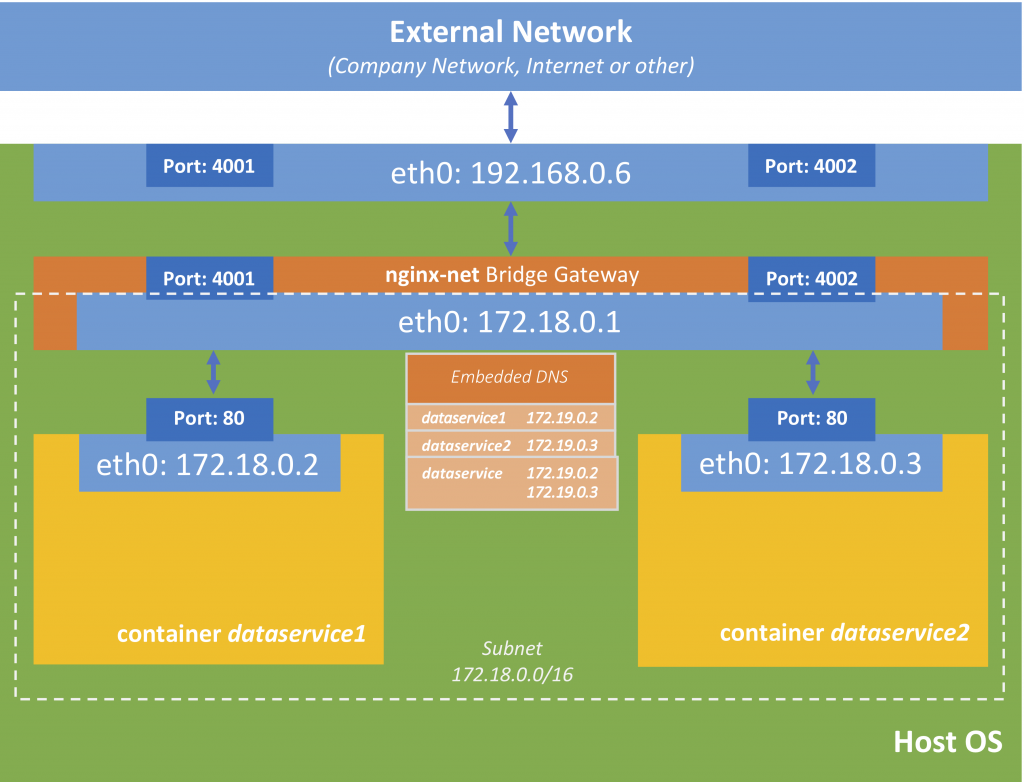
Let us take our dataService from the Swarm tutorial and create two Docker containers on the same host
docker container run --name dataservice1 -d -p4001:8080 vividbreeze/docker-tutorial:version1
docker container run --name dataservice2 -d -p4002:8080 vividbreeze/docker-tutorial:version1
So you call these services you should get a response with an id. This id should be different, depending on the port.
We used a new parameter called --alias. This alias is an alias for the embedded DNS service, i.e. that when I call dataservice inside of the dataservice-net, the embedded DNS will return the IP address from either dataservice1 or dataservice2. Let us test this by running a new container inside this network and executing curl dataservice:8080 (because inside of dataservice-net both containers listen to port 8080 on different IP-addresses).
docker container run --rm -it --network dataservice-net centos curl dataservice:8080
This command runs a new Docker container with CentOS, executes a curl (-it) and deletes itself afterwards (–rm).
If you repeat this command a couple of time, you see that the either one of the containers returns a result (you can see this on the different ids they return).
What is the beauty here? The loads (requests) is balanced between the two containers. If you stop one of the containers, a request to dataservice will still return a result.
docker container stop dataservice1
docker container run --rm -it --network dataservice-net centos curl dataservice:8080
We will later discuss, how we can use this DNS balancing from outside of the network.
Further Remarks
A bridge network can be reached by its IP address from the Docker host, when you are working on Linux (or from inside the Docker VM if you are working on MacOSX or Windows), but not by its name. The way you can access the containers from the host (also MacOSX and Windows) is by its ports on the local machine, e.g. curl 127.0.0.1:3000 or curl 192.168.0.6:3001.
If you are not exposing a port when running the container, the container won’t be accessible from outside of the bridge network (which is fine). This makes sense if you e.g have a service that connects to a database. The service should be accessible from the host network, while the database should only be accessed by the service.
A container can belong to several networks. You can try this by creating more of our small containers and connect them to our nginx-net or newly created networks.
In the first part of this series, we built a Docker swarm, consisting of just one node (our local machine). The nodes can act as swarm-managers and (or) swarm-workers. Now we want to create a swarm that spans more than one node (one machine).
Creating a Swarm
Creating the Infrastructure
First, we set up a cluster, consisting of Virtual Machines. We have used Vagrant before to create Virtual Machines on our local machine. Here, we will use docker-machine to create virtual machines on VirtualBox(you should have VirtualBox installed on your computer). docker-machine is a tool to create Docker VMs, however, it should not be used in production, where more configuration of a virtual machine is needed.
docker-machine uses a lightweight Linux distribution (boot2docker) including Docker, that will start within seconds (after the image was downloaded). As an alternative, you might use the alpine2docker Vagrant box.
Let us have a look at our virtual machines
docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
vm-manager - virtualbox Running tcp://192.168.99.104:2376 v18.06.0-ce
vm-worker1 - virtualbox Running tcp://192.168.99.105:2376 v18.06.0-ce
Setting Up the Swarm
As the name suggests, our first vm1 will be a swarm-manager, while the other two machines will be swarm-workers. Let us log into our first Virtual Machine and define it as a swarm-manager
docker-machine ssh vm-manager
docker swarm init
You might run into an error message such as
Error response from daemon: could not choose an IP address to advertise since this system has multiple addresses on different interfaces (10.0.2.15 on eth0 and 192.168.99.104 on eth1) - specify one with --advertise-addr
I initialised the swarm with the local address (192.168.99.104) on eth1. You will get the ip address of a machine, using
docker-machine ip vm-manager(outside of the VM)
So now let us try to initialise the swarm again
docker swarm init --advertise-addr 192.168.99.104
Swarm initialized: current node (9cnhj2swve2rynyh6fx7h72if) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2k1c6126hvjkch1ub74gea0hkcr1timpqlcxr5p4msm598xxg7-6fj5ccmlqdjgrw36ll2t3zr2t 192.168.99.104:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
The output displays the command to add a worker to the swarm. So now we can log into our two worker VMs and execute this command to initialise the swarm mode as a worker. You don’t have to open a secure shell on the VM explicitly; you can also execute a command on the VM directly
To see if everything ran smoothly, we can list the nodes in our swarm
docker-machine ssh vm-manager docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9cnhj2swve2rynyh6fx7h72if * vm-manager Ready Active Leader 18.06.0-ce
sfflcyts946pazrr2q9rjh79x vm-worker1 Ready Active 18.06.0-ce
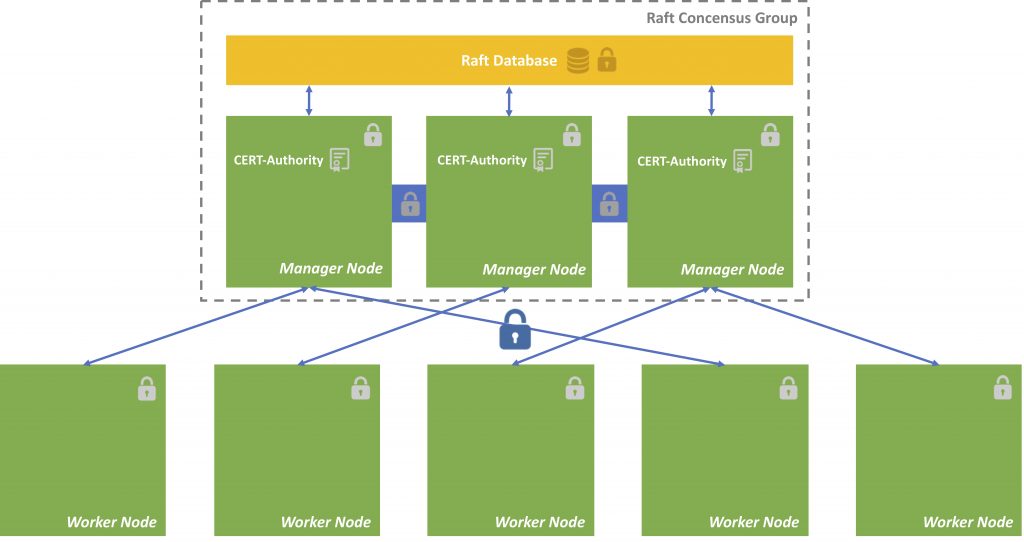
The main difference between a worker node and a manager node is that managers are workers that can control the swarm. The node I invoke swarm init, will become the swarm leader (and manager, by default). There can be several managers, but only one swarm leader.
During initialisation, a root certificate for the swarm is created, a certificate is issued for this first node and the join tokens for new managers and workers are created.
Most data is stored encrypted on the nodes. The communication inside of the swarm is encrypted.
Docker Swarm
Dictate Docker to run Commands against particular Node
Set environment variables to dictate that docker should run a command against a particular machine.
Running pre-create checks...
Creating machine...
(vm-manager) Copying /Users/vividbreeze/.docker/machine/cache/boot2docker.iso to /Users/vividbreeze/.docker/machine/machines/vm-manager/boot2docker.iso...
(vm-manager) Creating VirtualBox VM...
(vm-manager) Creating SSH key...
(vm-manager) Starting the VM...
(vm-manager) Check network to re-create if needed...
(vm-manager) Waiting for an IP...
Waiting for machine to be running, this may take a few minutes...
Detecting operating system of created instance...
Waiting for SSH to be available...
Detecting the provisioner...
Provisioning with boot2docker...
Copying certs to the local machine directory...
Copying certs to the remote machine...
Setting Docker configuration on the remote daemon...
Checking connection to Docker...
Docker is up and running!
To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env vm-manager
The last line tells you, how to connect your client (your machine), to the virtual machine you just created
docker-machine env vm-manager
exports the necessary docker environment variables with the values for the VM vm-manager
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://192.168.99.109:2376"
export DOCKER_CERT_PATH="/Users/vividbreeze/.docker/machine/machines/vm-manager"
export DOCKER_MACHINE_NAME="vm-manager"
# Run this command to configure your shell:
# eval $(docker-machine env vm-manager)
eval $(docker-machine env vm-manager)
dictates docker, to run all commands against vm-manager, e.g. the above docker node ls, or docker image ls etc. will also run against the VM vm-manager.
So now I can use docker node ls directly, to list the nodes in my swarm, as all docker commands now run against Docker on vm-manager (before I had to usedocker-machine ssh vm-manager docker node ls).
To reverse this command use docker-machine env -u and subsequently eval $(docker-machine env -u).
Deploying the Application
Now we can use the example from part I of the tutorial. Here is a copy of my docker-compose.yml, so you can follow this example (I increase the number of replicas from 3 to 5).
Let us deploy our service as describe in docker-compose.yml and name it dataservice
docker stack deploy -c docker-compose.yml dataapp
Creating network dataapp_default
Creating service dataapp_dataservice
Docker created a new service, called dataapp_dataservice and a network called dataapp_default. The network is a private network for the services that belong to the swarm to communicate with each other. We will have a closer look at networking in the next tutorial. So far nothing new as it seems.
Let us have a closer look at our dataservice
docker stack ps dataapp
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
s79brivew6ye dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running less than a second ago
gn3sncfbzc2s dataapp_dataservice.2 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running less than a second ago
wg5184iug130 dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running less than a second ago
i4a90y3hd6i6 dataapp_dataservice.4 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running less than a second ago
b4prawsu81mu dataapp_dataservice.5 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running less than a second ago
As you can see, the load was distributed to both VMs, no matter which role they have (swarm manager or swarm worker).
The requests can now go either against the IP of the VM manager or the VM worker. You can obtain its IP-address of the vm-manager with
docker-machine ip vm-manager
Now let us fire 10 requests against vm-manager to see if our service works
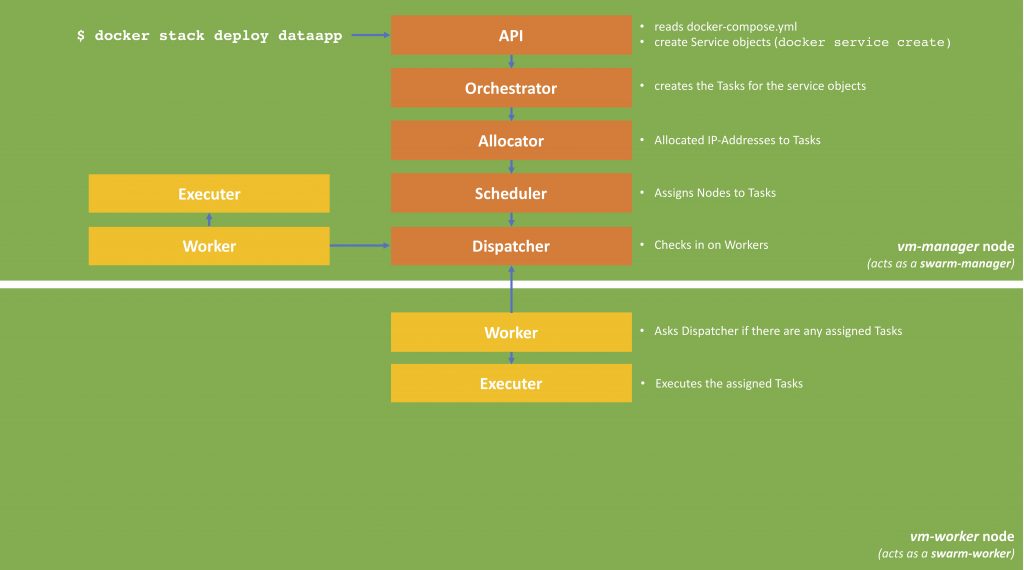
If everything is working, we should see five different kinds of responses (as five items were deployed in our swarm). The following picture describes shows how services are deployed.
Docker Stack Deployment Process
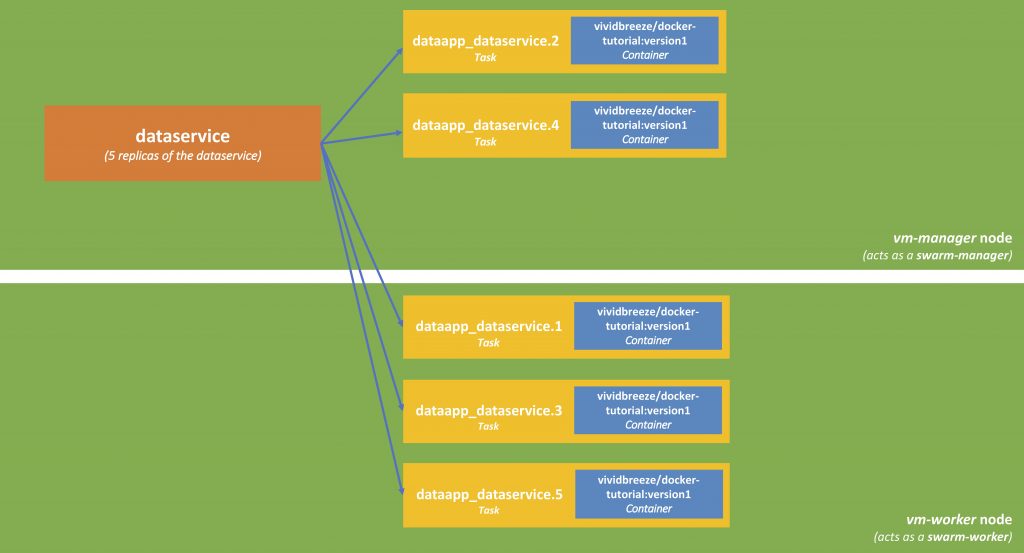
When we call docker stack deploy, the command transfers the docker-compose.yml to the swarm manager, the manager creates the services and deploys it to the swarm (as defined in the deploy-part of the docker-compose.yml). Each of the replicas (in our case 5) is called a task. Each task can be deployed on one or nodes (basically the container with the service-image is started on this node); this can be on a swarm-manager or swarm-worker. The result is depicted in the next picture.
Docker Service Deployment
Managing the Swarm
Dealing with a Crashed Node
In the last tutorial, we defined a restart-policy, so the swarm-manger will automatically start a new container, in case one crashes. Let us now see what happens when we remote our worker
docker-machine rm vm-worker1
We can see that while the server (vm-worker1) is shutting down, new tasks are created on the vm-manager
> docker stack ps dataservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
vc26y4375kbt dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 vm-manager Ready Ready less than a second ago
kro6i06ljtk6 \_ dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 vm-worker1 Shutdown Running 12 minutes ago
ugw5zuvdatgp dataapp_dataservice.2 vividbreeze/docker-tutorial:version1 vm-manager Running Running 12 minutes ago
u8pi3o4jn90p dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 vm-manager Ready Ready less than a second ago
hqp9to9puy6q \_ dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 vm-worker1 Shutdown Running 12 minutes ago
iqwpetbr9qv2 dataapp_dataservice.4 vividbreeze/docker-tutorial:version1 vm-manager Running Running 12 minutes ago
koiy3euv9g4h dataapp_dataservice.5 vividbreeze/docker-tutorial:version1 vm-manager Ready Ready less than a second ago
va66g4n3kwb5 \_ dataapp_dataservice.5 vividbreeze/docker-tutorial:version1 vm-worker1 Shutdown Running 12 minutes ago
A moment later you will see all 5 tasks running up again.
Dealing with Increased Workload in a Swarm
Increasing the number of Nodes
Let us now assume that the workload on our dataservice is growing rapidly. Firstly, we can distribute the load to more VMs.
As you can see when using docker stack ps dataapp, the tasks were not automatically deployed to the new VMs.
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
0rp9mk0ocil2 dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 vm-manager Running Running 18 minutes ago
3gju7xv20ktr dataapp_dataservice.2 vividbreeze/docker-tutorial:version1 vm-manager Running Running 13 minutes ago
wwi72sji3k6v dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 vm-manager Running Running 13 minutes ago
of5uketh1dbk dataapp_dataservice.4 vividbreeze/docker-tutorial:version1 vm-manager Running Running 13 minutes ago
xzmnmjnpyxmc dataapp_dataservice.5 vividbreeze/docker-tutorial:version1 vm-manager Running Running 13 minutes ago
The swarm-manager decides when to utilise new nodes. Its main priority is to avoid disruption of running services (even when they are idle). Of course, you can always force an update, which might take some time
docker service update dataapp_dataservice -f
Increasing the number of Replicas
In addition, we can also increase the number of replicas in our docker-compose.xml
Now rundocker stack deploy -c docker-compose.yml dataservice
docker stack ps dataapp shows that 5 new tasks (and respectively containers) have been created. Now the swarm-manager has utilised the new VMs.
D NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
0rp9mk0ocil2 dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 vm-manager Running Running 20 minutes ago
3gju7xv20ktr dataapp_dataservice.2 vividbreeze/docker-tutorial:version1 vm-manager Running Running 15 minutes ago
wwi72sji3k6v dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 vm-manager Running Running 15 minutes ago
of5uketh1dbk dataapp_dataservice.4 vividbreeze/docker-tutorial:version1 vm-manager Running Running 15 minutes ago
xzmnmjnpyxmc dataapp_dataservice.5 vividbreeze/docker-tutorial:version1 vm-manager Running Running 15 minutes ago
qn1ilzk57dhw dataapp_dataservice.6 vividbreeze/docker-tutorial:version1 vm-worker3 Running Preparing 3 seconds ago
5eyq0t8fqr2y dataapp_dataservice.7 vividbreeze/docker-tutorial:version1 vm-worker3 Running Preparing 3 seconds ago
txvf6yaq6v3i dataapp_dataservice.8 vividbreeze/docker-tutorial:version1 vm-worker2 Running Preparing 3 seconds ago
b2y3o5iwxmx1 dataapp_dataservice.9 vividbreeze/docker-tutorial:version1 vm-worker3 Running Preparing 3 seconds ago
rpov7buw9czc dataapp_dataservice.10 vividbreeze/docker-tutorial:version1 vm-worker3 Running Preparing 3 seconds ago
Further Remarks
To summarise
Use docker-machine (as an alternative to vagrant or others) to create VMs running Docker.
Use docker swarm to define a cluster that can run your application. The cluster can span physical machines and virtual machines (also in clouds). A machine can either be a manager or a worker.
Define your application in a docker-compose.yml.
Use docker stack to deploy your application in the swarm.
This again was a simple, pretty straightforward example. You can easily use docker-machine to create VMs in AWS E2 or Google Compute Engine and cloud services. Use this script to quickly install Docker on a VM.
A quick note, please always be aware on which machine you are working. You can easily get the Docker CLI to run against a different machine with docker-machine env vm-manager. To reverse this command use docker-machine env -u.
In the previous tutorial, we created one small service, and let it run in an isolated Docker container. In reality, your application might consist of many of different services. An e-commerce application encompasses services to register new customers, search for products, list products, show recommendations and so on. These services might even exist more than one time when they are heavily requested. So an application can be seen as a composition of different services (that run in containers).
In this first part of the tutorial, we will work with the simple application of the Docker Basics Tutorial, that contains only one service. We will deploy this service more than one time and let run on only one machine. In part II we will scale this application over many machines.
Prerequisites
Before we start, you should have completed the first part of the tutorial series. As a result, you should an image uploaded to the DockerHub registry. In my case, the image name is vividbreeze/docker-tutorial:version1.
Docker Swarm
As mentioned above, a real-world application consists of many containers spread over different hosts. Many hosts can be grouped to a so-called swarm (mainly hosts that run Docker in swarm-mode). A swarm is managed by one or more swarm managers and consists of one or many workers. Before we continue, we have to initial a swarm on our machine.
docker swarm init
Swarm initialized: current node (pnb2698sy8gw3c82whvwcrd77) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-39y3w3x0iiqppn57pf2hnrtoj867m992xd9fqkd4c3p83xtej0-9mpv98zins5l0ts8j62ociz4w 192.168.65.3:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
The swarm was initialised with one node (our machine) as a swarm manager.
Docker Stack
We now have to design our application. We do this in a file called docker-compose.yml. So far, we have just developed one service, and that runs inside one Docker container. In this part of the tutorial, our application will only consist of one service. Now let us assume this service is heavily used and we want to scale it.
The file contains the name of our service and the number of instances (or replicas) that should be deployed. We now do the port mapping here. The port 8080 that is used by the service inside of our container will be mapped to the port 4000 on our host.
To create our application use (you have to invoke this command from the vm-manager node)
docker stack deploy -c docker-compose.yml dataapp
Creating network dataapp_default
Creating service dataapp_dataservice
Docker now has created a network dataservice_web and a network dataservice_webnet. We will come to networking in the last part of this tutorial. By „stack“, Docker means a stack of (scaled) services that together form an application. A stack can be deployed on one swarm. It has to be called from a Swarm manager.
Let us now have a look, of how many containers were created
docker container ls
ONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bb18e9d71530 vividbreeze/docker-tutorial:version1 "java DataService" Less than a second ago Up 8 seconds dataapp_dataservice.3.whaxlg53wxugsrw292l19gm2b
441fb80b9476 vividbreeze/docker-tutorial:version1 "java DataService" Less than a second ago Up 7 seconds dataapp_dataservice.4.93x7ma6xinyde9jhearn8hjav
512eedb2ac63 vividbreeze/docker-tutorial:version1 "java DataService" Less than a second ago Up 6 seconds dataapp_dataservice.1.v1o32qvqu75ipm8sra76btfo6
In Docker terminology, each of these containers is called a task. Now each container cannot be accessed directly through the localhost and the port (they have no port), but through a manager, that listens to port 4000 on the localhost. These five containers, containing the same service, are bundled together and appear as one service. This service is listed by using
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
zfbbxn0rgksx dataapp_dataservice replicated 5/5 vividbreeze/docker-tutorial:version1 *:4000->8080/tcp
You can see the tasks (containers) that belong to this services with
docker service ps dataservice_web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
lmw0gnxcs57o dataapp_dataservice.1 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running 13 minutes ago
fozpqkmrmsb3 dataapp_dataservice.2 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running 13 minutes ago
gc6dccwxw53f dataapp_dataservice.3 vividbreeze/docker-tutorial:version1 linuxkit-025000000001 Running Running 13 minutes ago
Now let us call the service 10 times
repeat 10 { curl localhost:4000; echo }(zsh) for ((n=0;n<10;n++)); do curl localhost:4000; echo; done (bash)
Now you can see, that our service is called ten times, each time one of the services running inside of the containers were used to handle the request (you see three different ids). The service manager (dataservice-web) acts as a load-balancer. In this case, the load balancer uses a round-robin strategy.
To sum it up, in the docker-compose.yml, we defined our desired state (3 replicas of one service). Docker tries to maintain this desired state using the resources that are available. In our case, one host (one node). A swarm-manager manages the service, including the containers, we have just created. The service can be reached at port 4000 on the localhost.
Restart Policy
This can be useful for updating the number of replicas or changing other parameters. Let us play with some of the parameters. Let us add a restart policy to our docker-compose.yml
docker container ls -f "name=dataservice_web"
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
953e010ab4e5 vividbreeze/docker-tutorial:version1 "java DataService" 15 minutes ago Up 15 minutes dataapp_dataservice.1.pb0r4rkr8wzacitgzfwr5fcs7
f732ffccfdad vividbreeze/docker-tutorial:version1 "java DataService" 15 minutes ago Up 15 minutes dataapp_dataservice.3.rk7seglslg66cegt6nrehzhzi
8fb716ef0091 vividbreeze/docker-tutorial:version1 "java DataService" 15 minutes ago Up 15 minutes datasapp_dataservice.2.0mdkfpjxpldnezcqvc7gcibs8
Now let us kill one of these containers, to see if our manager will start a new one again
docker container rm -f 953e010ab4e5
It may take a few seconds, but then you will see a newly created container created by the swarm manager (the container-id of the first container is now different).
docker container ls -f "name=dataservice_web"
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bc8b6fa861be vividbreeze/docker-tutorial:version1 "java DataService" 53 seconds ago Up 48 seconds dataapp_dataservice.1.5aminmnu9fx8qnbzoklfbzyj5
f732ffccfdad vividbreeze/docker-tutorial:version1 "java DataService" 17 minutes ago Up 17 minutes dataapp_dataservice.3.rk7seglslg66cegt6nrehzhzi
8fb716ef0091 vividbreeze/docker-tutorial:version1 "java DataService" 18 minutes ago Up 17 minutes dataapp_datavervice.2.0mdkfpjxpldnezcqvc7gcibs8
The id in the response of one of the replicas of the service has changed
The service will be allocated to at most 50% CPU-time and 50 MBytes of memory, and at least 25% CPU-time and 5 MBytes of memory.
Docker Compose
Instead of docker stack, you can also use docker-compose. docker-compose is a program, written in Python, that does the container orchestration for you on a local machine, e.g. it ignores the deploy-part in the docker-compose.yml.
However, docker-compose uses some nice debugging and clean-up functionality, e.g. if you start our application with
docker-compose -f docker-compose.yml up
you will see the logs of all services (we only have one at the moment) colour-coded in your terminal window.
WARNING: Some services (web) use the 'deploy' key, which will be ignored. Compose does not support 'deploy' configuration - use `docker stack deploy` to deploy to a swarm.
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating network "docker_default" with the default driver
Pulling web (vividbreeze/docker-tutorial:version1)...
version1: Pulling from vividbreeze/docker-tutorial
Digest: sha256:39e30edf7fa8fcb15112f861ff6908c17d514af3f9fcbccf78111bc811bc063d
Status: Downloaded newer image for vividbreeze/docker-tutorial:version1
Creating docker_web_1 ... done
Attaching to docker_web_1
You can see in the warning, that the deploy part of your docker-compose.yml is ignored, as docker-compose focusses on the composition of services on your local machine, and not across a swarm.
If you want to clean up (containers, volumes, networks and other) just use
docker-compose down
docker-compose also allows you to build your images (docker stack won’t) in case it hasn’t been built before, e.g.
You might notice on the output of many commands, that docker-compose is different from the Docker commands. So again, use docker-compose only for Docker deployments on one host or to verify a docker-compose.yml on your local machine before using it in production.
Further Remarks
To summarise
Use docker swarm to define a cluster that runs our application. In our case the swarm consisted only of one machine (no real cluster). In the next part of the tutorial, we will see that a cluster can span various physical and virtual machines.
Define your application in a docker-compose.yml.
Use docker stack to deploy your application in the swarm in a production environment or docker-compose to test and deploy your application in a development environment.
Of course, there is more to Services, than I explained in this tutorial. However, I hope it helped as a starting point to go into more depth.
In this previous introduction, I explained the Docker basics. Now we will write a small web-service and deploy it inside of a Docker container.
Prerequisites
You should have Docker (community edition) installed on the machine you are working with. As I will use Java code, you should also have Java 8 (JDK) locally installed. In addition, please create a free account at DockerHub.
For the first steps, we will use this simple web service (DataService.java), that returns a short message and an id (random integer). This code is kept simple on purpose.
import javax.xml.transform.Source;
import javax.xml.transform.stream.StreamSource;
import javax.xml.ws.Endpoint;
import javax.xml.ws.Provider;
import javax.xml.ws.WebServiceProvider;
import javax.xml.ws.http.HTTPBinding;
import java.io.StringReader;
@WebServiceProvider
public class DataService implements Provider<Source> {
public static int RANDOM_ID = (int) (Math.random() * 5000);
public static String SERVER_URL = "http://0.0.0.0:8080/";
public Source invoke(Source request) {
return new StreamSource(new StringReader("<result><name>hello</name><id>" + RANDOM_ID + "</id></result>"));
}
public static void main(String[] args) throws InterruptedException {
Endpoint.create(HTTPBinding.HTTP_BINDING, new DataService()).publish(SERVER_URL);
Thread.sleep(Long.MAX_VALUE);
}
}
The web service listens to 0.0.0.0 (all IP4 addresses on the local machine) as we use this class inside a Docker container. If we would use 127.0.0.1 instead (the local interface inside of the container) requests from outside the request would not be handled.
To use the service, compile the source code by using
Now we want to run this service inside a Docker Container. Firstly, we have to build the Docker image. Therefore we will create a so-called Dockerfile with the following content.
FROM openjdk:8
COPY ./DataService.class /usr/services/dataservice/
WORKDIR /usr/services/dataservice
CMD ["java", "DataService"]
When Docker builds the image, you will see the different steps as well as a hash-code of the command. When you rebuild the image, Docker uses this hash-code to look for any changes. Docker will then only execute the command (and all subsequent commands) when the command has changed. Let us try this
docker build -t dataservice-image .
Sending build context to Docker daemon 580.1kB
Step 1/4 : FROM openjdk:8-alpine
---> 5801f7d008e5
Step 2/4 : COPY ./DataService.class /usr/src/dataservice/
---> Using cache
---> e539c7ae3991
Step 3/4 : WORKDIR /usr/src/dataservice
---> Using cache
---> 8e290a1cc598
Step 4/4 : CMD ["java", "DataService"]
---> Using cache
---> 25176dbe486b
Successfully built 25176dbe486b
Successfully tagged dataservice-image:latest
As nothing has changed, Docker uses the cached results and hence can build the image in less than a second. If we e.g. change step 2, all subsequent steps will run again.
Our image should now appear in the list of Docker images on our computer
docker images ls
REPOSITORY TAG IMAGE ID CREATED SIZE
dataservice-image latest d99051bca1c7 4 hours ago 624MB
openjdk 8 8c80ddf988c8 3 weeks ago 624MB
I highly recommend giving the image a name (-t [name] option) or a name and a tag (-t [name]:[tag]), as you are able to later reference the image by its name instead of its id.
Docker stores these image on your localhost, e.g. at /var/lib/docker/graph/<id> (Debian), or /Users/[user-name]/Library/Containers/com.docker.docker/Data on a Mac.
Other commands regarding the image that might become useful are
# get details information about the image (good for debugging)
docker image inspect dataservice-image
# delete an image
docker image rm dataservice-image
# remove all images
docker image rm $(docker image ls -a -q)
# remove all images (with force)
docker image rm -f $(docker image ls -a -q)
# show all docker image commands
docker image --help
Running the Container
Now that we build our image, we can finally run a container with our image
docker run --name dataservice-container -d -p4000:8080 dataservice-image
The -d option stands for daemon, i.e. the container runs as a background process. The -p option maps the container-internal port 8080, to a port on your local machine that runs docker (4000). The --name option gives the container a name, by which it can be referenced when using docker container commands.
You should now see the container in the list of all containers with
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4373e2dbcaee dataservice-image "java DataService" 3 minutes ago Up 4 minutes 0.0.0.0:4000->8080/tcp dataservice-container
If you don’t use the --name option, Docker will generate a name for you, e.g.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4373e2dbcaee dataservice-image "java DataService" 3 minutes ago Up 4 minutes 0.0.0.0:4000->8080/tcp distracted_hopper
Now let us call our service that resides inside the container with
The container now won’t appear when using docker container ls, as this command only shows the running containers. Use docker container ls -a instead.
Other useful commands for Docker containers are
# kills a container (stop - is a graceful shutdown (SIGTERM), while kill will kill the process inside the container (SIGKILL))
docker container dataservice-container
# removes a container, even if it is running
docker container rm dataservice-container
# removes all containers
docker container rm $(docker container ls -a -q)
# show STDOUT and STDERR from inside your container
docker logs --follow
# execute a command from inside your container
docker exec -it dataservice-container [command]
# log into your container
docker exec -it dataservice-container bash
# shows a list of other docker container commands
docker container --help
Publish your Image on DockerHub
So now that we have successfully created and run our first Docker Image, we can upload this image to a registry (in this case DockerHub) to use it from other machines.
Before we continue, I want to clarify the terms registry and repository, as well as the name-space that is used to identify an image. These terms are used a bit differently, than in other contexts (at least in my opinion) which might lead to confusion.
The Docker image itself represents a repository, similar to a repository in git. This repository can only exist local (as until now), or you can host it on a remote host (similar to GitHub or Bitbucket for git repositories). Services, that host repositories are called registries. GitHub or Bitbucket are registries that host git repositories. DockerHub, Artifactory or AWS Elastic Container Registry are registries that host Docker repositories (aka Docker images).
An image name is defined by a repository-name and a tag. The tag identifies the version of the image (such as 1.2.3 or latest). So the repository can contain different versions of the image.
Before we can push our Docker image to a registry (in this case DockerHub) we have to tag our image (this might seem a bit odd).
docker tag [image-name|image-id] [DockerHub user-name]/[repository-name]:[tag]
docker tag dataservice-image vividbreeze/docker-tutorial:version1
Now let us have a look at our images
docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
dataservice-image latest 61fe8918855a 10 minutes ago 624MB
vividbreeze/docker-tutorial version1 61fe8918855a 10 minutes ago 624MB
openjdk 8 8c80ddf988c8 3 weeks ago 624MB
You see the tagged-repository is listed with the same image-id. So both repository names are identifiers, that point to the same image. If you want to delete this link you have to use
Next, we have to log in your remote registry (DockerHub)
docker login
Now we can push the image to DockerHub
docker push vividbreeze/docker-tutorial:version1
If you log into DockerHub you should see the image (repository) (sometimes it might take a while before it appears in the list).
DockerHub Dashboard
To run this image use
docker run --name docker-container -d -p4000:8080 vividbreeze/docker-tutorial:version1
If the image is not present (which it now is), Docker would download the image from DockerHub before it runs it. You can try this if you delete the image and run the command above. You can also use this command from every other machine that runs docker.
So basically the command above downloads the image with the name vividbreeze/docker-tutorial and the tag version1 from your DockerHub registry.
You might notice that this image is very large (about 626 MB)
On DockerHub you will see that even the compressed size is 246 MB. The reason is, that the Java8 base-image and the images the base-image is based on are included in our image. You can decrease the size by using a smaller base-image, e.g. openjdk:8-alpine, which is based on Alpine Linux. In this case, the size of the image is only about 102 MB.
Troubleshooting
If you run into problems, I recommend having a look at the logs inside of your Docker container. You can access the messages that are written to STDOUT and STDERR with
docker logs
Often you can see if the start of your application has already failed or the call of a particular service. You can use the --follow option to continuously follow the log.
Next, I suggest logging into the Docker container to see if your service is running
docker exec -it dataservice-container bash
(you can call any Unix command inside of your container docker exec -it [container-name] [command]). In our example, try curl 127.0.0.1:8080. If the service is running correctly inside of the container, but you have problems calling the service from the outside, there might be a network problem, e.g. the port-mapping was wrong, the port is already in use etc. You can see the port-mapping with docker port docker-container.
However, you should make sure that the commands you execute in the container are available, e.g. if you use a small image, such as the alpine-Linux distribution, commands such as bash or curl won’t be available. So you have to use sh instead.
Another (sub-)command that is useful with (almost) all docker commands is inspect. It gives you all the information about an image, a container, a volume etc. that are available, such as mapped volumes, network information, environment variables etc.
docker image inspect dataservice-image
docker container inspect dataservice-container
Of course, there is more, but this basic knowledge should be sufficient to find the root cause of some problems you might run into.
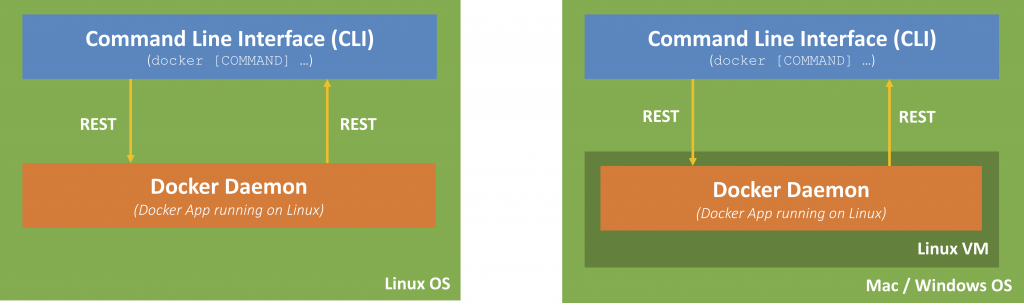
When we talk about Docker, we mainly talk about the Docker daemon, a process that runs on a host machine (in this tutorial most probably your computer). This Docker daemon is able to build images, run containers provide a network infrastructure and much more. The Docker daemon can be accessed via a REST interface. Docker provides a Command Line Interface (CLI), so you can access the Docker daemon directly from the command shell on the Docker host (docker COMMAND […|).
Docker Ecosystem
Docker is based on a Linux ecosystem. On a Mac or Windows, Docker will create a Virtual Machine (using HyperKit). The Docker daemon runs on this Virtual Machine. The CLI on your host will then communicate via the REST interface to the daemon on this Virtual Machine. Although you might not notice it, you should keep this in mind (see below).
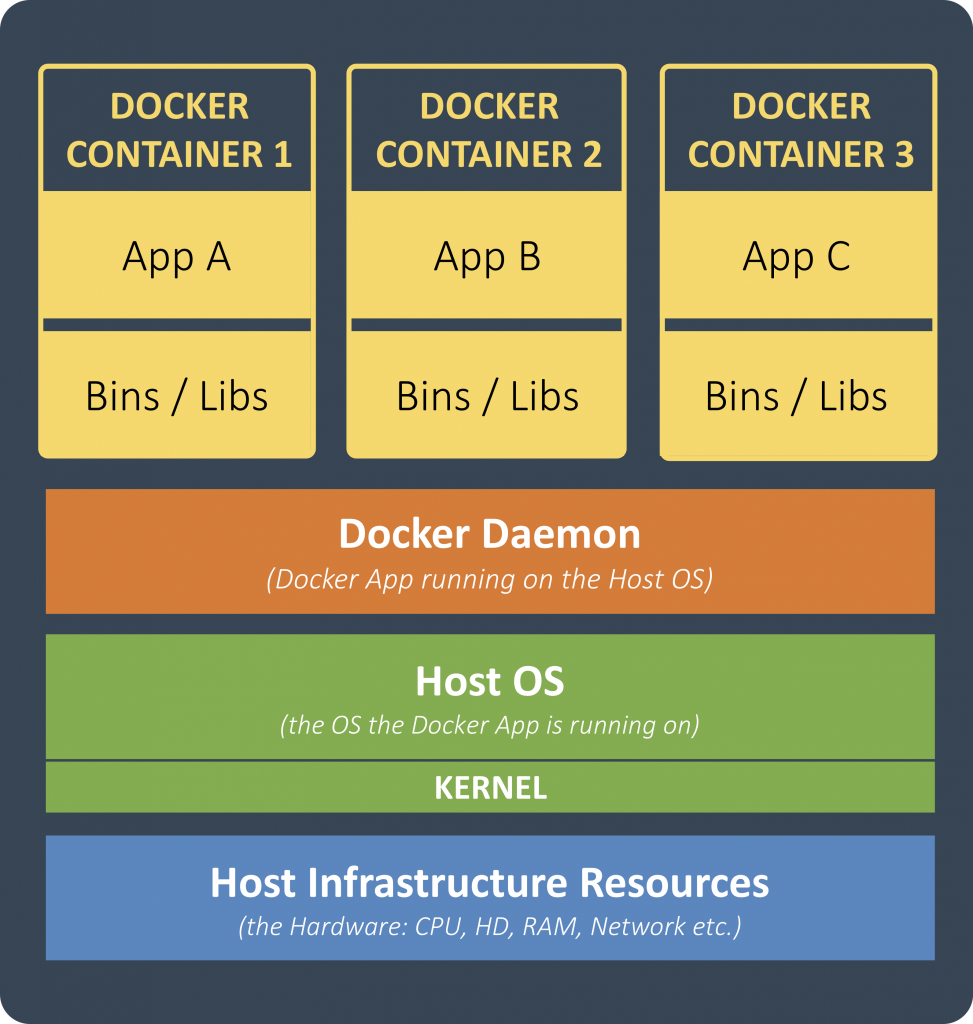
Docker Images
Docker runs an instance of an image in a so-called container. These images contain an application (such as nginx, MySQL, Jenkins, or OS such as Ubuntu) as well as the ecosystem to run this application. The ecosystem consists of the libraries and binaries that are needed to execute the application on a Linux machine. Most of the images are based on Linux distributions, as they already come with the necessary libraries and binaries. However, applications do not need a fully fledged Linux distribution, such as Ubuntu. Hence, most images are based on of a light-weight distribution such as Alpine Linux and others.
Docker Image
It should be recalled, that only the libraries and binaries of the Linux distribution inside of the image are necessary for the application to run. These libraries communicate with the Operating System on the Docker Host, mostly the kernel that in turn communicates with hardware. So the Linux distribution inside of your containers does not have to be booted. This makes the start-up time of the container incredibly fast, compared to Virtual Machines, that run an operating system (that has to be booted first).
Image Registry
DockerHub is a place where you can find the images that are publicly available. Some of these images are official images, maintained by Docker, most of them are customised images, provided by the community (other developers or organisations who decided to make their images public). You can now (also) find these images in the new DockerStore.
DockerHub
Docker Containers
When you start a container you basically run an image. If Docker can’t find the image on your host, docker will download it from a registry (which is DockerHub as a default). On your host, you can see this image running as one or more processes.
Docker Container
The beauty of containers is, that you can run and configure an application, without touching your host system.
Let us get started. In this introduction, we will run images that are available on DockerHub. In the next part, we will focus on custom-images. So let us build a container that contains a nginx web server.
docker run -d --name webserver -p 3001:80 nginx
What we are doing here is
running the Docker image nginx (the latest version, as we didn’t specify a tag)
mapping the port 80 (default port of nginx) to the port 3001 on the local host
running the Docker container detached (the container runs in the background)
naming the container webserver (so we can reference the container by its name for later operations)
If you are running Docker on a Linux OS, you should see two nginx processes in your process list. As mentioned above, if you are running Docker on MacOSX or Windows, Docker runs in a Virtual Machine. You can see the nginx process only when you log into this machine.
When you call localhost:3001 in your web browser, you should see the nginx default page.
You can list containers by using (use -a to list all containers, running and stopped ones)
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
590058dc3101 nginx "nginx -g 'daemon of…" 22 minutes ago Up 22 minutes 0.0.0.0:3001->80/tcp webserver
You can now stop the container, run it again or even delete the container with
docker container stop webserver
docker container start webserver
docker container rm webserver (if the container is still running, use -f for force as an option)
You can verify the current state with docker container ls -a.
Bind Mounts
So far we can only see the default nginx welcome screen in our web browser. If we want to show our own content, we can use a so-called bind mount. A bind mount maps a file or directory on the host machine to a file or directory in a container.
The nginx image we are using uses /usr/share/nginx/html as the default home for its HTML-files. We will bind this directory to the directory ~/docker/html on our local host (you might have to delete the current webserver-container before).
docker run -d --name webserver -p 3001:80 -v ~/docker/html:/usr/share/nginx/html nginx
So if you write a simple HTML-file (or any other file) to~/docker/html, you are able to access it in the web browser immediately.
Bind mounts are file-system specific, e.g. MacOSX uses a different file system them Windows, so the location pointer might look differently, such as /Users/chris on MacOSX and //c/Users/chris on Windows.
Volumes
Imagine you need a MySQL database for a short test. You can have MySQL up and running in Docker in seconds.
docker run -d --name database mysql
You might notice, that MySQL is strangely not running. Let us have a why this might be
docker container logs database
error: database is uninitialized and password option is not specified
You need to specify one of MYSQL_ROOT_PASSWORD, MYSQL_ALLOW_EMPTY_PASSWORD and MYSQL_RANDOM_ROOT_PASSWORD
As we could have seen in the official image description of MySQL, we needed to specify an environment variable that defines our initial password policy (mental note: always read the image description before you use it). Let us try this again (you might need to delete the container before: docker container rm database)
docker run -d -e MYSQL_ALLOW_EMPTY_PASSWORD=true --name database mysql
The database content will not be stored inside of the container but on the host as a so-called volume. You can list all volumes by using
docker volume ls
DRIVER VOLUME NAME
local 2362207fdc3f4a128ccc37aa45e729d5f0b939ffd38e8068346fcdddcd89fee7
You can find out to which location on the Docker host this volume is mapped by using the volume name
When MySQL writes into or reads from /var/lib/mysql, it actually writes into and read from the volume above. If you run Docker on a Linux host, you can go to this directory /var/lib/docker/volumes/2362207fdc3f4a128ccc37aa45e729d5f0b939ffd38e8068346fcdddcd89fee7/_data. If you run Docker on MacOSX or Windows, you have to log into the Linux VM that runs the Docker daemon first (see above).
This volume will outlive the container, meaning, if you remove the container, the volume will still be there – which is good in case you need to back up the contents.
docker container rm -f database
docker volume ls
DRIVER VOLUME NAME
local 2362207fdc3f4a128ccc37aa45e729d5f0b939ffd38e8068346fcdddcd89fee7
However, it can also leave lots of garbage on your computer, so make sure you delete volumes if you don’t use them. In addition, many containers create volumes but it is exhausting to find out which container a volume belongs to.
Another problem that remains is, that if you run a new MySQL container it will create a new volume. Of course, this makes sense, but what happens, if you just want to update to a new version of MySQL?
Same as bindings above, you can name volumes
docker run -d -e MYSQL_ALLOW_EMPTY_PASSWORD=true -v db1:/var/lib/mysql --name database mysql
So when you now look at your volumes now, you will see the new volume with the name db1
docker volume ls
DRIVER VOLUME NAME
local 2362207fdc3f4a128ccc37aa45e729d5f0b939ffd38e8068346fcdddcd89fee7
local db1
Connect to this database, e.g. using MySQL Workbench or any other database client, create a database, a table, and insert some data into this table.
(Another option would be to log into the container itself and start a mysql session to create a database: docker container exec -it database bash. This command executes bash in the container in an interactive terminal).
Now delete the container database
docker container rm -f database
You will notice (docker volume ls) that our volume is still there. Now create a new MySQL container with the identical volume
docker run -d -e MYSQL_ALLOW_EMPTY_PASSWORD=true -v db1:/var/lib/mysql --name database mysql
Use your database client to connect to MySQL. The database, table and its contents should still be there.
What is the different between a Volume and a Bind Mount
a Volume is created by using the Docker file system, which is the same, not matter on which OS the Docker daemon is running. A volume can by anonymous (just referenced by an id) or named.
a Bind Mount, on the other hand, binds a file or directory on the Docker host (which can be Linux, MacOSX or Windows) to a file or directory in the container. Bind Mounts rely on the specific directory structure of the filesystem on the host machine (which is different in Linux, MacOSX and Unix). Hence, Docker doesn’t allow to use bind mounts to create new images. You can only specify bind mounts in the command using the -v parameter.
Further Remarks
This short tutorial just covered some basics to get around with Docker. I recommend to play a bit with the Docker CLI and also try the different options. In the next part, we will build and run a customised image.
In the Ansible introduction, we build a Playbook to install Jenkins from scratch on a remote machine. The Playbook was simple (for education purposes), it was designed for Debian Linux distributions (we used apt as a package manager), it just provided an out-of-the-box Jenkins (without any customisation). Thus, the Playbook is not very re-usable or configurable.
However, if we would have made it more complex, the single-file Playbook would have become difficult to read and maintain and thus more error-prone.
To overcome these problems, Ansible specified a directory structure where variables, handlers, tasks and more are put into different directories. This grouped content is called an Ansible Role. A Role must include at least one of these directories.
You can find plenty of these Roles design by the Ansible community in the Ansible Galaxy. Let me show some examples to explain the concept of Ansible Roles.
How to use Roles
I highly recommend using popular Ansible Roles to perform provisioning of common software than writing your own Playbooks, as it might be more versatile and less error-prone, e.g. to install Java, Apache or nginx, Jenkins and other.
Ansible Galaxy
Let us assume we want to install an Apache HTTP server. The most popular Role with over 300.000 downloads was written by geerlingguy, one of the most popular contributors to the Ansible Galaxy. I will jump right into the GitHub Repository of this Role.
Firstly, you always have to install the role using the command line,
ansible-galaxy install [role-name] e.g.
ansible-galaxy install geerlingguy.apache
Roles are downloaded from the Ansible Galaxy and stored locally at ~/.ansible/roles or /etc/ansible/roles/ (use ansible --version if you are not sure).
In most cases, the README.md provides sufficient information on how to use this role. Basically, you define the hosts, on which the play is being executed, the variables to configure the role, and the role itself. In case of the Apache Role, the Playbook (ansible.yml) might look like this
I won’t go too much into how to design Roles, as the Ansible documentation already provides a good documentation. Roles must include at least one of the directories, mentioned in the documentation. In reality, they look less complex, e.g. the Apache Ansible Role we used in this example, looks like
Directory Structure of Ansible Role to install Apache
The default-variables including a documentation are defined in defaults/main.yml, the tasks to install Apache can be found in /tasks/main.yml, that in turn calls the OS-specific Playbooks for RedHat, Suse, Solaris and Debian.
Further Remarks
Ansible Roles give good examples of how to use Ansible Playbooks in general. So if you are new to Ansible and want to understand some of the concepts in more detail, I recommend having a look at the Playbooks in the Ansible Galaxy.
As mentioned above, I highly recommend using pre-defined roles for installing common software packages. In most cases, it will give you fewer headaches, especially if these Roles are sufficiently tested, which can be assumed for the most popular ones.
This tutorial builds up upon the previous introductions to Vagrant and Ansible. Firstly, we will set up a Vagrant Box with Amazon Web Services (AWS). Subsequently, we will use the Ansible script to configure Jenkins in this Box, using the same Playbook as in the previous blog post.
Prerequisites
Setting up an AWS Account
I assume that you have no AWS account yet. Please register for an AWS account and choose the Basic Plan. If you are new to AWS, Amazon provides a so-called AWS Free Tier that lets you test AWS for 12 months.
The web-interface can be very confusing at times as AWS is a powerful tool that provides tons of services. Here we will solely focus on the Elastic Compute Cloud (EC2). Before you configure our Vagrantfile, we will have to set-up AWS. For the sake of simplicity and focus, I will only get into details if necessary.
Create a new Access Key
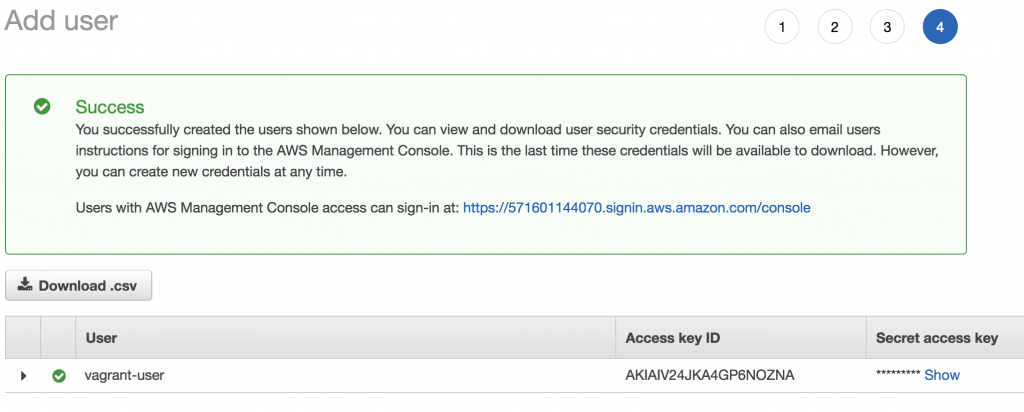
First of all, we need to create an access key. It is not recommended, to work with the root security credentials, as they give full access to your AWS account. Please add a new user using the IAM console(Identity and Access Management). I added a user named vagrant-user with Programmatic Access. I add this user to a group I call admin and give this group AdministratorAccess (we can change this later).
AWS Add User
After the user was successfully added, I retrieve the Access Key ID and the Secret Access Key. Please store this information as it won’t be available again. These credentials are needed to create a new EC2 instance with Vagrant.
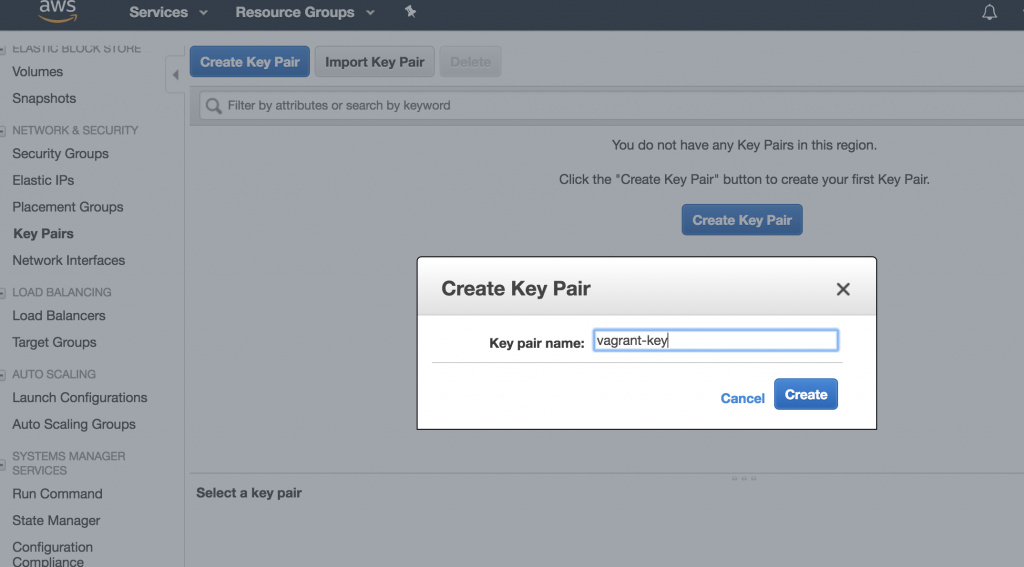
Create a new Key Pair
A new Key-Pair can be created in the EC2 console(Services -> EC2 -> Key Pairs). This Key-Pair is used for SSH access to your EC2 instance, once the instance was created. I choose the name vagrant-key.
AWS Create a new Key Pair
The public key will be stored in AWS, the private key file is automatically downloaded (in this case vagrant-key.pem). Store this key in a safe place and set permission to read-only for the current user (chmod 400 vagrant-key.pem).
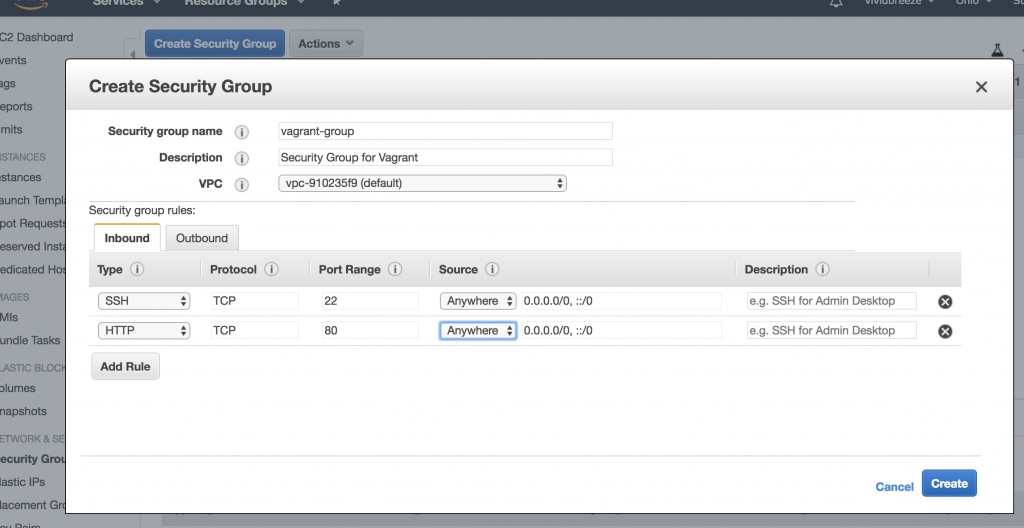
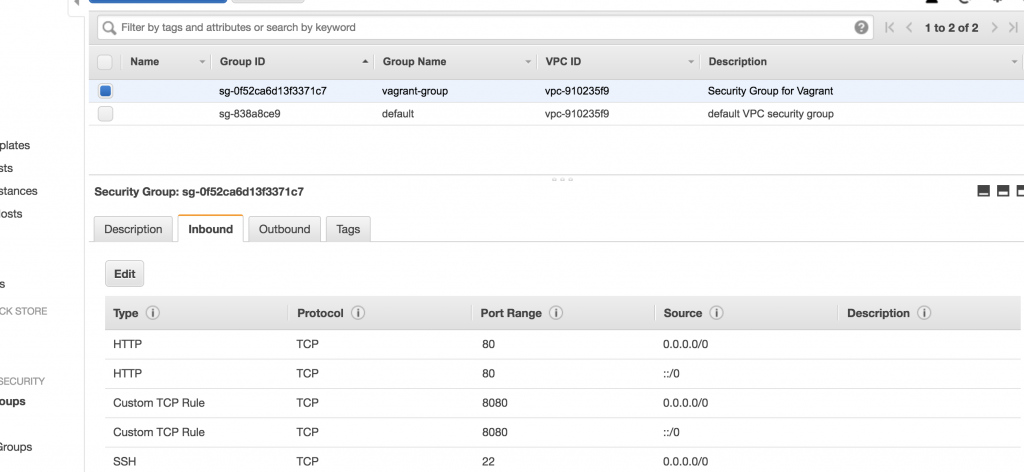
Creating a Security Group
Next, we have to create a Security Group to allow an SSH (and optionally an HTTP) connection to the EC instance. The connection to the EC2 instance will be created when the EC2 instance is created by Vagrant. You can use the default-group that should already exist or create a new group. I will create a group called vagrant-group and allow SSH and HTTP from anywhere (inbound-traffic).
Creating an AWS Security Group
Choose an Image
Images in EC2 are called AMI (Amazon Machine Image) and are identified by an ID (e.g. ami-8c122be9). The IDs are region-specific, i.e. not every image is available in any region. This is important as you will set the AMI and the region in the provider configuration in your Vagrantfile later, and you will run into errors if the AMI is not available in your region.
My AWS account is in the us-east-2 region (the region will show up in your EC2 dashboard) and I choose the image Ubuntu Server 16.04 LTS (HVM), SSD Volume Type with the IDami-5e8bb23b (as we used an Ubuntu distribution for our VirtualBox in the Vagrant tutorial). We need this information later in our Vagrantfile.
Preparing Vagrant
Adding the Vagrant AWS Provider
As Vagrant doesn’t come with a built-in AWS provider, it has to be installed manually as a plugin
vagrant plugin install vagrant-aws
To check if the plugin was successfully installed use (the plugin should appear in the list)
vagrant plugin list
Adding a Vagrant Dummy Box
The definition of a Vagrant box is mandatory in the Vagrantfile. If you work with AWS you will use Amazon Machine Images (as mentioned above). Hence, the definition of a Vagrant box is only a formality. For this purpose, the author of the AWS plugin for Vagrant has created a dummy-box. To add this box to Vagrant use:
When launching the instance, I encountered the problem that I was asked for SMB credentials (on MacOS!). I solved this problem by disabling folder-sync as mentioned in the support forum.
The ssh-username depends on the AMI, for the selected Ubuntu-AMI, the username is „ubuntu“, for the Amazon Linux 2 AMI (HVM), SSD Volume Type (ami-8c122be9), it is „ec2-user“.
In addition, I install Python as a pre-requisite for Ansible
As for instance type I chose a small t2.micro instance (1 Virtual CPU, 1 GB RAM), that is included in the AWS Free Tier.
Launching the EC2 Instance
To launch the instance, use
vagrant up --provider=aws
In the console, you should see an output similar to
Bringing machine 'default' up with 'aws' provider...
==> default: Warning! The AWS provider doesn't support any of the Vagrant
==> default: high-level network configurations (`config.vm.network`). They
==> default: will be silently ignored.
==> default: Launching an instance with the following settings...
==> default: -- Type: t2.micro
==> default: -- AMI:ami-5e8bb23b
==> default: -- Region: us-east-2
==> default: -- Keypair: vagrant-key
==> default: -- Security Groups: ["vagrant-group"]
==> default: -- Block Device Mapping: []
==> default: -- Terminate On Shutdown: false
==> default: -- Monitoring: false
==> default: -- EBS optimized: false
==> default: -- Source Destination check:
==> default: -- Assigning a public IP address in a VPC: false
==> default: -- VPC tenancy specification: default
==> default: Waiting for instance to become "ready"...
==> default: Waiting for SSH to become available...
==> default: Machine is booted and ready for use!
If you encounter any problems, you can call vagrant up in debug-mode
vagrant up --provider=aws --debug
You know should be able to see the EC2 instance in the EC2 console in the state running. The security group we created earlier (vagrant-should) should have been linked. In this view, you can also retrieve the public DNS and IP address to access this instance from the Internet.
AWS EC2 Instance Overview
You can now access the instance using
vagrant ssh
In addition, you can log into your EC2 instance using SSH and your DNS
If everything works smoothly, Jenkins should now be installed on your EC2 instance.
If you run into an authentification error (access denied) you might have to add the public SSH key of your EC2 instance to the authentication agent with
ssh-add vagrant-key.pem
Before you can access Jenkins you have to allow an inbound connection on port 8080 in the Security Groupvagrant-group (we previously created).
Opening Port 8080 to access Jenkins
If you now call the URL (or IP address) of the EC2 instance in your browser on Port 8080, you should see the Jenkins installation-screen. Voilà.
Of course, there are more elegant ways to construct the Vagrantfile, e.g. by reading the credentials from environment variables or from ~/.aws. I have chosen this format for sake of simplicity. There are also many more configuration options than describe here. Please have a further look at the vagrant-aws documentation.
Make sure to destroy your EC2 instance when you don’t need it anymore, as it will consume your credits. The Billing Dashboard provides a good summary of your usage.